
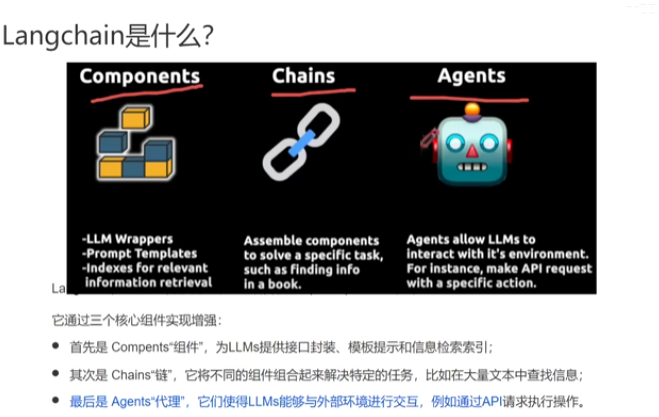
环境与安装
安装langchain包
# 创建 RAG_langchain-main环境
pip install langchain==0.0.316
pip install openai==0.28.1
from langchain.chat_models import ChatOpenAI
os.environ["OPENAI_API_KEY"] = "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"
# 导入模型(ChatOpenAI其实只代表一种协议,使用别的模型只要遵守这个api协议,都可以用这个函数)
chat = ChatOpenAI(
openai_api_key=os.environ["OPENAI_API_KEY"],
model='gpt-3.5-turbo'
)
from langchain.schema import (
SystemMessage,
HumanMessage,
AIMessage
)
messages = [
SystemMessage(content="You are a helpful assistant."),
HumanMessage(content="Knock knock."),
AIMessage(content="Who's there?"),
HumanMessage(content="Orange"),
]
res = chat(messages)
直接用包langchain_openai
langchain-openai包通过OpenAI SDK包含了OpenAI的LangChain集成。
- 安装
#创建环境
conda create -n langchain_env pip python=3.8.10
conda activate langchain_env
#安装langchain_openai
pip install langchain_openai
- 配置与使用
# chatgpt 接口
from langchain_openai import ChatOpenAI
# 提示词格式化
from langchain_core.messages import HumanMessage, SystemMessage
# 解析器
from langchain_core.output_parsers import StrOutputParser
# Step1 创建模型
llm = ChatOpenAI(
model='deepseek-r1',
api_key="sk-4df4224d959345ed9284bf5cbe36fbd0",
openai_api_base='https://dashscope.aliyuncs.com/compatible-mode/v1')
# Step2 准备提示词
message = [
SystemMessage(content='请将以下的内容翻译成英文:'),
HumanMessage(content='你好,请问你要去哪里')
]
# Step3 创建输出解析器
paser = StrOutputParser()
# Step4 得到操作链
chain = llm | paser
# Step5 链式操作
chain.invoke(message)
print(chain.invoke(message))
调用Model
https://python.langchain.com/docs/integrations/chat/
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
# 1. 实例化模型对象
model = ChatOpenAI(model="gpt-4o")
# 2. 调用模型
# invoke 是最标准的调用方式
response = model.invoke([HumanMessage(content="你好,你是谁?")])
print(response.content)
#链式调用
chain = prompt | model | output_parser
result = chain.invoke({"input": "介绍一下量子力学"})
输入:prompt_template模板
使用提示模版,可以让我们更为方便地重复使用设计好的提示。英文版提示2.2.3 给出了作业的提示模版案例:学生们线上学习并提交作业,通过提示来实现对学生的提交的作业的评分。
此外,LangChain还提供了提示模版用于一些常用场景。比如自动摘要、问答、连接到SQL数据库、连接到不同的API。通过使用LangChain内置的提示模版,你可以快速建立自己的大模型应用,而不需要花时间去设计和构造提示
from langchain.prompts import ChatPromptTemplate
# 首先,构造一个提示模版字符串:`template_string`
template_string = """把由三个反引号分隔的文本\
翻译成一种{style}风格。\
文本: ```{text}```
"""
# 然后,我们调用`ChatPromptTemplatee.from_template()`函数将# 上面的提示模版字符`template_string`转换为提示模版`prompt_template`
prompt_template = ChatPromptTemplate.from_template(template_string)
print("\n", prompt_template.messages[0].prompt)
# input_variables=['style', 'text'] output_parser=None partial_variables={} template='把由三个反引号分隔的文本翻译成一种{style}风格。文本: ```{text}```\n' template_format='f-string' validate_template=True
#提示模版prompt_template需要两个输入变量: style 和 text。 这里分别对应
#customer_style: 我们想要的顾客邮件风格
#customer_email: 顾客的原始邮件文本
customer_style = """正式普通话 \
用一个平静、尊敬的语气
"""
customer_email = """
嗯呐,我现在可是火冒三丈,我那个搅拌机盖子竟然飞了出去,把我厨房的墙壁都溅上了果汁!
更糟糕的是,保修条款可不包括清理我厨房的费用。
伙计,赶紧给我过来!
"""# 使用提示模版
customer_messages = prompt_template.format_messages(
style=customer_style,
text=customer_email)
# 打印客户消息类型 list
print("客户消息类型:",type(customer_messages),"\n")
# 打印第一个客户消息类型 列表里的元素变量类型为langchain自定义消息(langchain.schema.HumanMessage)。
print("第一个客户客户消息类型类型:", type(customer_messages[0]),"\n")
# 打印第一个元素
print("第一个客户客户消息类型类型: ", customer_messages[0],"\n")
输出格式
with_structured_output
它的核心作用是:强制大模型(LLM)按照你定义的结构(如 JSON 或 Pydantic 模型)输出数据,而不是返回一段自由文本。
用法
通常只需要三个步骤:定义结构、绑定模型、调用。
第一步:定义输出结构(pydantic、typeDict、JSON Schema)
推荐使用 Pydantic,因为它不仅能定义字段,还能自带校验逻辑。
from pydantic import BaseModel, Field
class ExtractInfo(BaseModel):"""提取文本中的人物和地点信息"""
name: str = Field(description="人的姓名")
location: str = Field(description="居住或提到的地点")
不是所有模型都支持使用pydantic, 不想使用 Pydantic,也可以直接传入 TypedDict 或 JSON Schema。
# 使用 JSON Schema 示例
json_schema = {
"title": "get_weather",
"description": "获取指定城市的温度",
"type": "object",
"properties": {
"city": {"type": "string"},
"unit": {"enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
structured_llm = llm.with_structured_output(json_schema)
第二步:实例化模型并绑定
你可以直接在支持工具调用的模型(如 GPT-4, Claude 3, Gemini 等)上调用此方法。
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o")
# 将模型转化为“结构化模型”
structured_llm = llm.with_structured_output(ExtractInfo)
可选参数:method
可选参数:指定解析模式method,method 参数决定了模型通过何种“底层协议”来生成结构化数据
- function_calling (默认模式) 这是目前最通用、最智能的模式。它利用了模型提供商(如 OpenAI, Anthropic, Gemini)专门为工具调用(Tool Calling)训练的能力。
- 工作原理:LangChain 会将你的 Pydantic 模型或 Schema 转换成一个“虚构函数”的定义发送给模型,并告诉模型:“请调用这个函数来回答问题”。
- 优点:支持复杂的嵌套结构;模型通常对此有专门的微调,遵循性极高。
- 适用场景:绝大多数情况(尤其是使用
gpt-4o,claude-3-5-sonnet等现代模型时)。
structured_llm = llm.with_structured_output(Joke, method="function_calling")
- json mode 模式 这种模式强制模型输出一个有效的 JSON 字符串。 工作原理:它开启模型原生的“JSON 模式”(如果模型支持),确保输出流以 { 开始并以 } 结束。 局限性: 你必须在 Prompt 中明确说明输出格式(例如:“请输出 JSON 格式的内容”)。 它不如 function_calling 稳定,因为模型只是在生成文本,而不是在“执行指令”。 适用场景:当模型不支持 Tool Calling,或者你需要更原生的 JSON 控制时。
# 注意:使用 json_mode 时,Prompt 必须包含 "JSON" 字样
prompt = ChatPromptTemplate.from_template("请用 JSON 格式讲个笑话:{topic}")
structured_llm = llm.with_structured_output(Joke, method="json_mode")
chain = prompt | structured_llm
- json_schema (OpenAI 专用) 这是 OpenAI 特有的 Structured Outputs 功能。 工作原理:与普通的 function_calling 不同,OpenAI 会在推理层级强制约束输出,保证 100% 符合你定义的 Schema(如果格式不对,模型根本无法生成 Token)。 优点:绝对的格式保障,拒绝任何随机性导致的解析错误。 适用场景:对格式准确性要求极高的金融、法律或自动化工作流。
第三步:调用并获取对象
返回的结果不再是 AIMessage,而是你定义的 ExtractInfo 对象。
result = structured_llm.invoke("张三住在北京的胡同里")
print(result.name) # 输出: 张三
print(result.location) # 输出: 北京
output_parsers 输出解释器
response = chat(messages)
获得的response.content只能是String,不一定是我们要求的dict或者json等格式,这时候就需要输出解释器进行进一步转换
review_template_2 = """\
对于以下文本,请从中提取以下信息::
礼物:该商品是作为礼物送给别人的吗?
如果是,则回答 是的;如果否或未知,则回答 不是。
交货天数:产品到达需要多少天? 如果没有找到该信息,则输出-1。
价钱:提取有关价值或价格的任何句子,并将它们输出为逗号分隔的 Python 列表。
文本: {text}
{format_instructions}
"""
prompt = ChatPromptTemplate.from_template(template=review_template_2)
from langchain.output_parsers import ResponseSchema
from langchain.output_parsers import StructuredOutputParser
gift_schema = ResponseSchema(name="礼物",
description="这件物品是作为礼物送给别人的吗?\
如果是,则回答 是的,\
如果否或未知,则回答 不是。")
delivery_days_schema = ResponseSchema(name="交货天数",
description="产品需要多少天才能到达?\
如果没有找到该信息,则输出-1。")
price_value_schema = ResponseSchema(name="价钱",
description="提取有关价值或价格的任何句子,\
并将它们输出为逗号分隔的 Python 列表")
response_schemas = [gift_schema,
delivery_days_schema,
price_value_schema]
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
print("输出格式规定:",format_instructions)
response = chat(messages)
output_dict = output_parser.parse(response.content)
print("解析后的结果类型:", type(output_dict)) # dict
print("解析后的结果:", output_dict)
调用工具tools
在 LangChain 和 LangGraph 中,工具(Tools)的定义和调用遵循 “定义 -> 绑定 -> 触发 -> 执行” 的标准流程。
定义工具 (Defining Tools)
最推荐的方式是使用 @tool 装饰器。它会自动将 Python 函数的名称、文档字符串(Docstring)和参数类型提示转换为大模型(LLM)可以理解的 JSON Schema。
Python
from langchain_core.tools import tool
@tool
def get_weather(city: str):
"""查询指定城市的实时天气。"""# 这里的代码是工具的实际逻辑
if city.lower() == "shanghai":
return "晴天,25°C"
注意:文档字符串非常重要,模型依靠它来判断何时该使用这个工具。
将工具绑定到模型 (Binding Tools)
定义好工具后,你需要告诉模型这些工具的存在。通过 .bind_tools() 方法,将工具的结构传给模型。
Python
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o")
# 将工具列表绑定到模型实例
model_with_tools = model.bind_tools([get_weather])
调用工具 (Calling Tools)
这里是 LangChain 和 LangGraph 出现分歧的地方:
A. 在 LangChain 中(手动/链式)
在简单的链中,模型并不会自动执行工具函数。它只是返回一个“调用请求”(tool_calls)。
Python
# 1. 模型决定调用工具
ai_msg = model_with_tools.invoke("上海天气怎么样?")
# 2. 提取工具调用请求for tool_call in ai_msg.tool_calls:
# 3. 手动执行工具(或通过工具执行器)
if tool_call["name"] == "get_weather":
result = get_weather.invoke(tool_call["args"])
print(result)
B. 在 LangGraph 中(自动化循环)
LangGraph 的核心优势在于它有一个内置的 ToolNode,可以自动处理模型生成的 tool_calls 并返回结果。
Python
from langgraph.prebuilt import ToolNode
from langgraph.graph import StateGraph, START, END
# 1. 定义工具节点
tool_node = ToolNode([get_weather])
# 2. 定义逻辑:判断模型输出是否包含工具调用def should_continue(state):
messages = state["messages"]
last_message = messages[-1]
if last_message.tool_calls:
return "tools"return END
# 3. 构建图
workflow = StateGraph(MessagesState)
workflow.add_node("agent", call_model) # 这里面调用 model_with_tools
workflow.add_node("tools", tool_node) # 自动执行工具逻辑
workflow.add_edge(START, "agent")
# 根据模型结果决定:是去执行工具,还是直接结束
workflow.add_conditional_edges("agent", should_continue)
workflow.add_edge("tools", "agent") # 工具执行完后,回到模型进行总结
app = workflow.compile()
存储Memory
当使用 LangChain 中的储存(Memory)模块时,它旨在保存、组织和跟踪整个对话的历史,从而为用户和模型之间的交互提供连续的上下文。
LangChain 提供了多种储存类型。其中,缓冲区储存允许保留最近的聊天消息,摘要储存则提供了对整个对话的摘要。实体储存则允许在多轮对话中保留有关特定实体的信息。这些记忆组件都是模块化的,可与其他组件组合使用,从而增强机器人的对话管理能力。储存模块可以通过简单的 API 调用来访问和更新,允许开发人员更轻松地实现对话历史记录的管理和维护。
对话缓存储存 (ConversationBufferMemory)
- 保存对话内容
from langchain.chains import ConversationChain
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
# 这里我们将参数temperature设置为0.0,从而减少生成答案的随机性。# 如果你想要每次得到不一样的有新意的答案,可以尝试增大该参数。
llm = ChatOpenAI(temperature=0.0)
memory = ConversationBufferMemory()# 新建一个 ConversationChain Class 实例# verbose参数设置为True时,程序会输出更详细的信息,以提供更多的调试或运行时信息。# 相反,当将verbose参数设置为False时,程序会以更简洁的方式运行,只输出关键的信息。
conversation = ConversationChain(llm=llm, memory = memory, verbose=True )
#第一轮对话
conversation.predict(input="你好, 我叫皮皮鲁")
#第二轮对话
conversation.predict(input="1+1等于多少?")
#第三轮对话
conversation.predict(input="我叫什么名字?")
# 输出 '你叫皮皮鲁。',依旧会记得之前对话的内容
print(memory.buffer)
Human: 你好, 我叫皮皮鲁
AI: 你好,皮皮鲁!很高兴认识你。我是一个AI助手,可以回答你的问题和提供帮助。有什么我可以帮你的吗?
Human: 1+1等于多少?
AI: 1+1等于2。
Human: 我叫什么名字?
AI: 你叫皮皮鲁。
# 打印字典形式
print(memory.load_memory_variables({}))
- 预加载一些信息进去
memory = ConversationBufferMemory()
memory.save_context({"input": "你好,我叫皮皮鲁"}, {"output": "你好啊,我叫鲁西西"})
memory.load_memory_variables({})
对话缓存窗口储存 (ConversationBufferWindowMemory)
随着对话变得越来越长,所需的内存量也变得非常长。将大量的tokens发送到LLM的成本,也会变得更加昂贵,这也就是为什么API的调用费用,通常是基于它需要处理的tokens数量而收费的。
针对以上问题,LangChain也提供了几种方便的储存方式来保存历史对话。其中,对话缓存窗口储存只保留一个窗口大小的对话。它只使用最近的n次交互。这可以用于保持最近交互的滑动窗口,以便缓冲区不会过大。
- 保存k轮对话内容
from langchain.memory import ConversationBufferWindowMemory
llm = ChatOpenAI(temperature=0.0)
memory = ConversationBufferWindowMemory(k=1)
conversation = ConversationChain(llm=llm, memory=memory, verbose=False )
print("第一轮对话:")
print(conversation.predict(input="你好, 我叫皮皮鲁"))
print("第二轮对话:")
print(conversation.predict(input="1+1等于多少?"))
print("第三轮对话:")
print(conversation.predict(input="我叫什么名字?"))
第一轮对话:
你好,皮皮鲁!很高兴认识你。我是一个AI助手,可以回答你的问题和提供帮助。有什么我可以帮你的吗?
第二轮对话:
1+1等于2。
第三轮对话:
很抱歉,我无法知道您的名字。
- 预存一些内容
# k=1表明只保留一个对话记忆
memory = ConversationBufferWindowMemory(k=1)
memory.save_context({"input": "你好,我叫皮皮鲁"}, {"output": "你好啊,我叫鲁西西"})
memory.save_context({"input": "很高兴和你成为朋友!"}, {"output": "是的,让我们一起去冒险吧!"})
memory.load_memory_variables({})
#{'history': 'Human: 很高兴和你成为朋友!\nAI: 是的,让我们一起去冒险吧!'}
对话令牌缓存储存 (ConversationTokenBufferMemory)
使用对话字符缓存记忆,内存将限制保存的token数量。如果字符数量超出指定数目,它会切掉这个对话的早期部分 以保留与最近的交流相对应的字符数量,但不超过字符限制。
from langchain.llms import OpenAI
from langchain.memory import ConversationTokenBufferMemory
memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=30)
memory.save_context({"input": "朝辞白帝彩云间,"}, {"output": "千里江陵一日还。"})
memory.save_context({"input": "两岸猿声啼不住,"}, {"output": "轻舟已过万重山。"})
memory.load_memory_variables({})
# 打印结果
{'history': 'AI: 轻舟已过万重山。'}
ChatGPT 使用一种基于字节对编码(Byte Pair Encoding,BPE)的方法来进行 tokenization (将输入文本拆分为token)。BPE 是一种常见的 tokenization 技术,它将输入文本分割成较小的子词单元。 OpenAI 在其官方 GitHub 上公开了一个最新的开源 Python 库 tiktoken(https://github.com/openai/tiktoken)%EF%BC%8C%E8%BF%99%E4%B8%AA%E5%BA%93%E4%B8%BB%E8%A6%81%E6%98%AF%E7%94%A8%E6%9D%A5%E8%AE%A1%E7%AE%97),这个库主要是用来计算%EF%BC%8C%E8%BF%99%E4%B8%AA%E5%BA%93%E4%B8%BB%E8%A6%81%E6%98%AF%E7%94%A8%E6%9D%A5%E8%AE%A1%E7%AE%97) tokens 数量的。相比较 HuggingFace 的 tokenizer ,其速度提升了好几倍。 具体 token 计算方式,特别是汉字和英文单词的 token 区别,具体可参考知乎文章(https://www.zhihu.com/question/594159910)%E3%80%82)。%E3%80%82)
对话摘要缓存储存 (ConversationSummaryBufferMemory)
对话摘要缓存储存,使用 LLM 对到目前为止历史对话自动总结摘要,并将其保存下来。
- 对话存储
conversation = ConversationChain(llm=llm, memory=memory, verbose=True)
conversation.predict(input="展示什么样的样例最好呢?")
print(memory.load_memory_variables({})) # 摘要记录更新了
- 直接预存
from langchain.chains import ConversationChain
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationSummaryBufferMemory
# 创建一个长字符串
schedule = "在八点你和你的产品团队有一个会议。 \
你需要做一个PPT。 \
上午9点到12点你需要忙于LangChain。\
Langchain是一个有用的工具,因此你的项目进展的非常快。\
中午,在意大利餐厅与一位开车来的顾客共进午餐 \
走了一个多小时的路程与你见面,只为了解最新的 AI。 \
确保你带了笔记本电脑可以展示最新的 LLM 样例."
llm = ChatOpenAI(temperature=0.0)
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=100)
memory.save_context({"input": "你好,我叫皮皮鲁"}, {"output": "你好啊,我叫鲁西西"})
memory.save_context({"input": "很高兴和你成为朋友!"}, {"output": "是的,让我们一起去冒险吧!"})
memory.save_context({"input": "今天的日程安排是什么?"}, {"output": f"{schedule}"})print(memory.load_memory_variables({})['history'])
模型链Chains
LLM Chain
import warnings
warnings.filterwarnings('ignore')from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
# 这里我们将参数temperature设置为0.0,从而减少生成答案的随机性。# 如果你想要每次得到不一样的有新意的答案,可以尝试调整该参数。
llm = ChatOpenAI(temperature=0.0)
prompt = ChatPromptTemplate.from_template("描述制造{product}的一个公司的最佳名称是什么?")
chain = LLMChain(llm=llm, prompt=prompt)
#如果我们有一个名为"Queen Size Sheet Set"的产品,我们可以通过使用chain.run将其通过这个链运行
product = "大号床单套装"
chain.run(product)
SimpleSequentialChain
简单顺序链(SimpleSequentialChain),这是顺序链的最简单类型,其中每个步骤都有一个输入/输出,一个步骤的输出是下一个步骤的输入。
from langchain.chains import SimpleSequentialChain
llm = ChatOpenAI(temperature=0.9)
# 提示模板 1 :这个提示将接受产品并返回最佳名称来描述该公司
first_prompt = ChatPromptTemplate.from_template(
"描述制造{product}的一个公司的最好的名称是什么")
chain_one = LLMChain(llm=llm, prompt=first_prompt)# 提示模板 2 :接受公司名称,然后输出该公司的长为20个单词的描述
second_prompt = ChatPromptTemplate.from_template(
"写一个20字的描述对于下面这个\
公司:{company_name}的"
)
chain_two = LLMChain(llm=llm, prompt=second_prompt)
overall_simple_chain = SimpleSequentialChain(chains=[chain_one, chain_two], verbose=True)
product = "大号床单套装"
overall_simple_chain.run(product)
SequentialChains
当有多个输入或多个输出时,我们则需要使用顺序链(SequentialChain)来实现。
#创建四个子链
#子链1
# prompt模板 1: 翻译成英语(把下面的review翻译成英语)
first_prompt = ChatPromptTemplate.from_template("把下面的评论review翻译成英文:""\n\n{Review}")# chain 1: 输入:Review 输出:英文的 Review
chain_one = LLMChain(llm=llm, prompt=first_prompt, output_key="English_Review")
#子链2
# prompt模板 2: 用一句话总结下面的 review
second_prompt = ChatPromptTemplate.from_template("请你用一句话来总结下面的评论review:""\n\n{English_Review}")
# chain 2: 输入:英文的Review 输出:总结
chain_two = LLMChain(llm=llm, prompt=second_prompt, output_key="summary")#
#子链3
# prompt模板 3: 下面review使用的什么语言
third_prompt = ChatPromptTemplate.from_template("下面的评论review使用的什么语言:\n\n{Review}")
# chain 3: 输入:Review 输出:语言
chain_three = LLMChain(llm=llm, prompt=third_prompt, output_key="language")
#子链4
# prompt模板 4: 使用特定的语言对下面的总结写一个后续回复
fourth_prompt = ChatPromptTemplate.from_template("使用特定的语言对下面的总结写一个后续回复:""\n\n总结: {summary}\n\n语言: {language}")# chain 4: 输入: 总结, 语言 输出: 后续回复
chain_four = LLMChain(llm=llm, prompt=fourth_prompt, output_key="followup_message")
#组合四个子链
#输入:review #输出:英文review,总结,后续回复
overall_chain = SequentialChain(
chains=[chain_one, chain_two, chain_three, chain_four],
input_variables=["Review"],
output_variables=["English_Review", "summary","followup_message"],
verbose=True)
#使用
df = pd.read_csv('../data/Data.csv')
review = df.Review[5]
overall_chain(review)
Router Chain
想做一些更复杂的事情怎么办?一个相当常见但基本的操作是根据输入将其路由到一条链,具体取决于该输入到底是什么。如果你有多个子链,每个子链都专门用于特定类型的输入,那么可以组成一个路由链,它首先决定将它传递给哪个子链,然后将它传递给那个链。
路由器由两个组件组成:
-
路由链(Router Chain):路由器链本身,负责选择要调用的下一个链
-
destination_chains:路由器链可以路由到的链
from langchain.chains.router import MultiPromptChain #导入多提示链from langchain.chains.router.llm_router import LLMRouterChain,RouterOutputParser
from langchain.prompts import PromptTemplate
llm = ChatOpenAI(temperature=0)
- 准备一些prompt,并对其进行起名
# 中文#第一个提示适合回答物理问题
physics_template = """你是一个非常聪明的物理专家。 \
你擅长用一种简洁并且易于理解的方式去回答问题。\
当你不知道问题的答案时,你承认\
你不知道.
这是一个问题:
{input}"""#第二个提示适合回答数学问题
math_template = """你是一个非常优秀的数学家。 \
你擅长回答数学问题。 \
你之所以如此优秀, \
是因为你能够将棘手的问题分解为组成部分,\
回答组成部分,然后将它们组合在一起,回答更广泛的问题。
这是一个问题:
{input}"""#第三个适合回答历史问题
history_template = """你是以为非常优秀的历史学家。 \
你对一系列历史时期的人物、事件和背景有着极好的学识和理解\
你有能力思考、反思、辩证、讨论和评估过去。\
你尊重历史证据,并有能力利用它来支持你的解释和判断。
这是一个问题:
{input}"""#第四个适合回答计算机问题
computerscience_template = """ 你是一个成功的计算机科学专家。\
你有创造力、协作精神、\
前瞻性思维、自信、解决问题的能力、\
对理论和算法的理解以及出色的沟通技巧。\
你非常擅长回答编程问题。\
你之所以如此优秀,是因为你知道 \
如何通过以机器可以轻松解释的命令式步骤描述解决方案来解决问题,\
并且你知道如何选择在时间复杂性和空间复杂性之间取得良好平衡的解决方案。
这还是一个输入:
{input}"""
# 中文
prompt_infos = [
{"名字": "物理学",
"描述": "擅长回答关于物理学的问题",
"提示模板": physics_template
},
{"名字": "数学",
"描述": "擅长回答数学问题",
"提示模板": math_template
},
{"名字": "历史",
"描述": "擅长回答历史问题",
"提示模板": history_template
},
{"名字": "计算机科学",
"描述": "擅长回答计算机科学问题",
"提示模板": computerscience_template
}]
- 创建目标链和默认目标链(兜底)
destination_chains = {}
for p_info in prompt_infos:
name = p_info["名字"]
prompt_template = p_info["提示模板"]
prompt = ChatPromptTemplate.from_template(template=prompt_template)
chain = LLMChain(llm=llm, prompt=prompt)
destination_chains[name] = chain
destinations = [f"{p['名字']}: {p['描述']}" for p in prompt_infos]
destinations_str = "\n".join(destinations)
default_prompt = ChatPromptTemplate.from_template("{input}")
default_chain = LLMChain(llm=llm, prompt=default_prompt)
- 构建路由链
router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(
destinations=destinations_str
)
router_prompt = PromptTemplate(
template=router_template,
input_variables=["input"],
output_parser=RouterOutputParser(),)
router_chain = LLMRouterChain.from_llm(llm, router_prompt)
- 构建整体链路
#多提示链
chain = MultiPromptChain(router_chain=router_chain, #l路由链路
destination_chains=destination_chains, #目标链路
default_chain=default_chain, #默认链路
verbose=True
)
基于RAG的问答
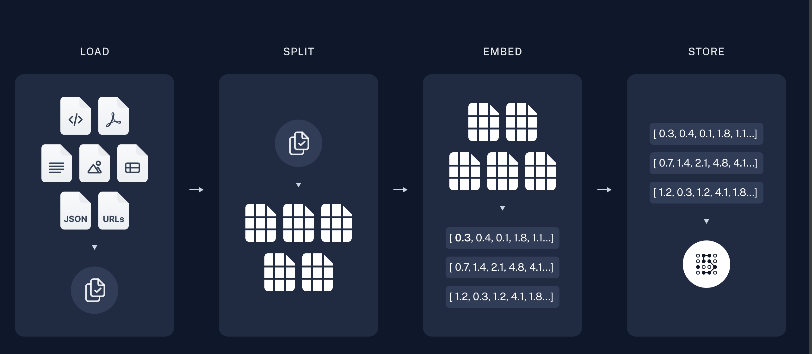
Document loaders文件加载器
pdf文件下载器
pip install pypdf
from langchain.document_loaders import PyPDFLoader
# 创建一个 PyPDFLoader Class 实例,输入为待加载的pdf文档路径
loader = PyPDFLoader("../data/baichuan.pdf")
# 调用 PyPDFLoader Class 的函数 load对pdf文件进行加载
# pages的数据结构是一个List类型
pages = loader.load()
print(type(pages))
print(len(pages))
# 每一页的type为 <class 'langchain.schema.document.Document'>
page = pages[0]
print(type(page))
# Document的page_content属性为pdf文件中该页的内容
print(page.page_content[0:500])
# metadata为pdf文件中该页的描述性数据,比如页数等
print(page.metadata)
Youtube音频
pip install yt_dlp
pip install pydub
from langchain.document_loaders.generic import GenericLoader
from langchain.document_loaders.parsers import OpenAIWhisperParser
from langchain.document_loaders.blob_loaders.youtube_audio import YoutubeAudioLoader
url = "https://youtu.be/_2XkoG6h92w?si=XI1fqD6RVsJHNzge"
save_dir = ""
# 创建一个 GenericLoader Class 实例
loader = GenericLoader(
# 将链接url中的Youtube视频的音频下载下来,存在本地路径save_dir
YoutubeAudioLoader([url], save_dir),
# 使用OpenAIWhisperPaser解析器将音频转化为文本
OpenAIWhisperParser()
)
# 调用 GenericLoader Class 的函数 load对视频的音频文件进行加载
pages = loader.load()
print(type(pages[0])) # 同样是document
网页文档
from langchain.document_loaders import WebBaseLoader
# 创建一个 WebBaseLoader Class 实例
url = "https://github.com/datawhalechina/d2l-ai-solutions-manual/blob/master/docs/README.md"
header = {'User-Agent': 'python-requests/2.27.1',
'Accept-Encoding': 'gzip, deflate, br',
'Accept': '*/*','Connection': 'keep-alive'}
loader = WebBaseLoader(web_path=url,header_template=header)# 调用 WebBaseLoader Class 的函数 load对文件进行加载
pages = loader.load()
print("Type of pages: ", type(pages))
print("Length of pages: ", len(pages))
page = pages[0]
print("Type of page: ", type(page))
print("Page_content: ", page.page_content[:500])
print("Meta Data: ", page.metadata)
Type of pages: <class 'list'>
Length of pages: 1
Type of page: <class 'langchain.schema.document.Document'>
Page_content: {"payload":{"allShortcutsEnabled":false,"fileTree":{"docs":{"items":[{"name":"ch02","path":"docs/ch02","contentType":"directory"},{"name":"ch03","path":"docs/ch03","contentType":"directory"},{"name":"ch05","path":"docs/ch05","contentType":"directory"},{"name":"ch06","path":"docs/ch06","contentType":"directory"},{"name":"ch08","path":"docs/ch08","contentType":"directory"},{"name":"ch09","path":"docs/ch09","contentType":"directory"},{"name":"ch10","path":"docs/ch10","contentType":"directory"},{"na
Meta Data: {'source': 'https://github.com/datawhalechina/d2l-ai-solutions-manual/blob/master/docs/README.md'}
可以看到上面的文档内容包含许多冗余的信息。通常来讲,我们需要进行对这种数据进行进一步处理(Post Processing)
import json
convert_to_json = json.loads(page.page_content)
extracted_markdown = convert_to_json['payload']['blob'['richText']
print(extracted_markdown)
notion文档(Markdown )
from langchain.document_loaders import NotionDirectoryLoader
loader = NotionDirectoryLoader("docs/Notion_DB")
pages = loader.load()
print("Type of pages: ", type(pages))
print("Length of pages: ", len(pages))
page = pages[0]
print("Type of page: ", type(page))
print("Page_content: ", page.page_content[:500])
print("Meta Data: ", page.metadata)
文本分割 split
为什么分割文档
-
模型大小和内存限制:GPT 模型,特别是大型版本如 GPT-3 或 GPT-4 ,具有数十亿甚至上百亿的参数。为了在一次前向传播中处理这么多的参数,需要大量的计算能力和内存。但是,大多数硬件设备(例如 GPU 或 TPU )有内存限制。文档分割使模型能够在这些限制内工作。
-
计算效率:处理更长的文本序列需要更多的计算资源。通过将长文档分割成更小的块,可以更高效地进行计算。
-
序列长度限制:GPT 模型有一个固定的最大序列长度,例如2048个 token 。这意味着模型一次只能处理这么多 token 。对于超过这个长度的文档,需要进行分割才能被模型处理。
-
更好的泛化:通过在多个文档块上进行训练,模型可以更好地学习和泛化到各种不同的文本样式和结构。
-
数据增强:分割文档可以为训练数据提供更多的样本。例如,一个长文档可以被分割成多个部分,并分别作为单独的训练样本。
怎么分割
Langchain 中文本分割器都根据 chunk_size (块大小)和 chunk_overlap (块与块之间的重叠大小)进行分割。
Langchain提供多种文档分割方式,区别在怎么确定块与块之间的边界、块由哪些字符/token组成、以及如何测量块大小

基于字符分割
CharacterTextSplitter 是字符文本分割,分隔符的参数是单个的字符串;
RecursiveCharacterTextSplitter ,类似于滑动窗口分割,是递归字符文本分割,将按不同的字符递归地分割(按照这个优先级["\n\n", "\n", " ", ""]),这样就能尽量把所有和语义相关的内容尽可能长时间地保留在同一位置。因此,RecursiveCharacterTextSplitter 比 CharacterTextSplitter 对文档切割得更加碎片化
RecursiveCharacterTextSplitter 需要关注的是如下4个参数:
-
separators分隔符字符串数组 -
chunk_size每个文档的字符数量限制 -
chunk_overlap两份文档重叠区域的长度 -
length_function长度计算函数
- 短句分割
# 导入文本分割器
from langchain.text_splitter import RecursiveCharacterTextSplitter, CharacterTextSplitter
chunk_size = 20 #设置块大小
chunk_overlap = 10 #设置块重叠大小
# 初始化递归字符文本分割器
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
# 初始化字符文本分割器
c_splitter = CharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
# CharacterTextSplitter默认转行为划分分隔符,如果没有转行就不划分呢
# 设置逗号空格分隔符
c_splitter2 = CharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separator=','
)
text = "在AI的研究中,由于大模型规模非常大,模型参数很多,在大模型上跑完来验证参数好不好训练时间成本很高,所以一般会在小模型上做消融实验来验证哪些改进是有效的再去大模型上做实验。" #测试文本
r_splitter.split_text(text)
c_splitter.split_text(text)
print("RecursiveCharacterTextSplitter: ", r_splitter.split_text(text))
print("CharacterTextSplitter: ", c_splitter.split_text(text))
- 长文本分割
c_splitter = CharacterTextSplitter(
chunk_size=80,
chunk_overlap=0,
separator=' ')'''
对于递归字符分割器,依次传入分隔符列表,分别是双换行符、单换行符、空格、空字符,
因此在分割文本时,首先会采用双分换行符进行分割,同时依次使用其他分隔符进行分割
'''
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=80,
chunk_overlap=0,
separators=["\n\n", "\n", " ", ""])
基于token分割
很多 LLM 的上下文窗口长度限制是按照 Token 来计数的。因此,以 LLM 的视角,按照 Token 对文本进行分隔,通常可以得到更好的结果。 通过一个实例理解基于字符分割和基于 Token 分割的区别
可以看出token长度和字符长度不一样,token通常为4个字符
# 使用token分割器进行分割,# 将块大小设为1,块重叠大小设为0,相当于将任意字符串分割成了单个Token组成的列from langchain.text_splitter import TokenTextSplitter
text_splitter = TokenTextSplitter(chunk_size=1, chunk_overlap=0)
text = "foo bar bazzyfoo"
text_splitter.split_text(text)# 注:目前 LangChain 基于 Token 的分割器还不支持中文
['foo', ' bar', ' b', 'az', 'zy', 'foo']
分割Markdown 文档
# 定义一个Markdown文档from langchain.document_loaders import NotionDirectoryLoader#Notion加载器from langchain.text_splitter import MarkdownHeaderTextSplitter#markdown分割器
markdown_document = """# Title\n\n \
## 第一章\n\n \
李白乘舟将欲行\n\n 忽然岸上踏歌声\n\n \
### Section \n\n \
桃花潭水深千尺 \n\n
## 第二章\n\n \
不及汪伦送我情"""
# 定义想要分割的标题列表和名称
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on
)#message_typemessage_type
md_header_splits = markdown_splitter.split_text(markdown_document)
print("第一个块")
print(md_header_splits[0])
print("第二个块")
print(md_header_splits[1])
嵌入模型(Embedding Models)
Embeddings(嵌入)是一种将类别数据,如单词、句子或者整个文档,转化为实数向量的技术。这些实数向量可以被计算机更好地理解和处理。嵌入背后的主要想法是,相似或相关的对象在嵌入空间中的距离应该很近
from langchain.embeddings.openai import OpenAIEmbeddings
embedding = OpenAIEmbeddings()
sentence1_chinese = "我喜欢狗"
sentence2_chinese = "我喜欢犬科动物"
sentence3_chinese = "外面的天气很糟糕"
embedding1_chinese = embedding.embed_query(sentence1_chinese)
embedding2_chinese = embedding.embed_query(sentence2_chinese)
embedding3_chinese = embedding.embed_query(sentence3_chinese)
import numpy as np
# 通过dot计算相似度 相似度越高 则语义越相近
print(np.dot(embedding1_chinese, embedding2_chinese)) #0.9440614936689298
print(np.dot(embedding1_chinese, embedding3_chinese)) # 0.792186975021313
print(np.dot(embedding2_chinese, embedding3_chinese)) #0.7804109942586283
向量储存(Vector Stores)
Langchain集成了超过30个不同的向量存储库。我们选择Chroma是因为它轻量级且数据存储在内存中,这使得它非常容易启动和开始使用。
from langchain.vectorstores import Chroma
# 指定一个持久化路径
persist_directory_chinese = 'docs/chroma/matplotlib/'
# 初始化
#允许我们将persist_directory目录保存到磁盘上
vectordb_chinese = Chroma.from_documents(
documents=splits,
embedding=embedding,
persist_directory=persist_directory_chinese )
# 数据库检索
question_chinese = "Matplotlib是什么?"
docs_chinese = vectordb_chinese.similarity_search(question_chinese,k=3)
print(docs_chinese[0].page_content)
检索(Retrieval)(相似度)
检索是指根据用户的问题去向量数据库中搜索与问题相关的文档内容,当我们访问和查询向量数据库时可能会运用到如下几种技术:
-
基本语义相似度(Basic semantic similarity)
-
最大边际相关性(Maximum marginal relevance,MMR)
-
过滤元数据
-
LLM辅助检索
向量数据库检索技术
- 相似度检索
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
persist_directory_chinese = 'docs/chroma/matplotlib/'
embedding = OpenAIEmbeddings()
vectordb_chinese = Chroma(
persist_directory=persist_directory_chinese,
embedding_function=embedding
)
smalldb_chinese = Chroma.from_texts(texts_chinese, embedding=embedding)
print(vectordb_chinese._collection.count())
question_chinese = "告诉我关于具有大型子实体的全白色蘑菇的信息"
# 返回2个最相关的文档
smalldb_chinese.similarity_search(question_chinese, k=2)
- 解决多样性:最大边界相关性MMR
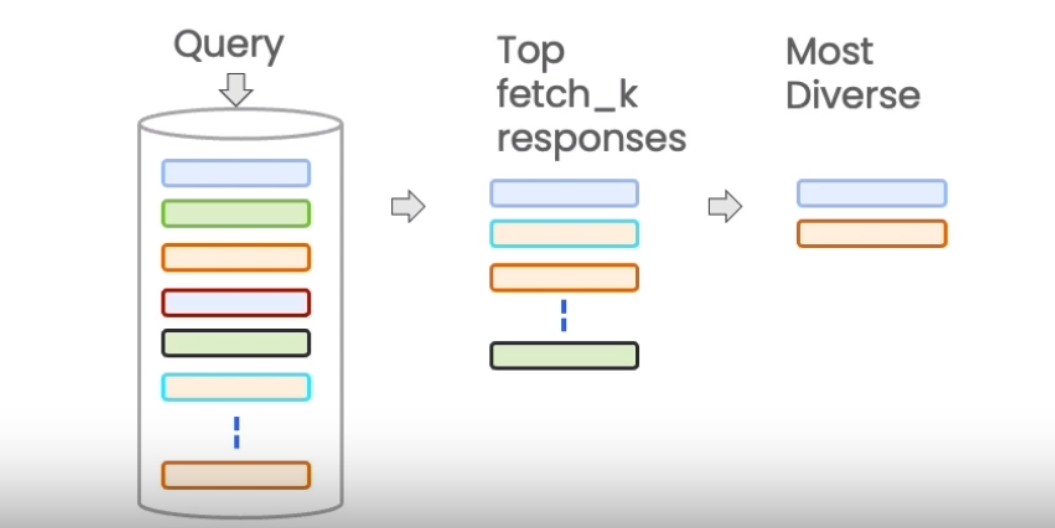 MMR 的基本思想是同时考量查询与文档的相关度,以及文档之间的相似度。相关度确保返回结果对查询高度相关,相似度则鼓励不同语义的文档被包含进结果集。具体来说,它计算每个候选文档与查询的相关度,并减去与已经选入结果集的文档的相似度。这样更不相似的文档会有更高的得分。
MMR 的基本思想是同时考量查询与文档的相关度,以及文档之间的相似度。相关度确保返回结果对查询高度相关,相似度则鼓励不同语义的文档被包含进结果集。具体来说,它计算每个候选文档与查询的相关度,并减去与已经选入结果集的文档的相似度。这样更不相似的文档会有更高的得分。
smalldb_chinese.max_marginal_relevance_search(question_chinese,k=2, fetch_k=3)
- 解决特殊性:使用元数据
是询问了关于文档中某一讲的问题,但得到的结果中也包括了来自其他讲的结果。这是我们所不希望看到的结果,之所以产生这样的结果是因为当我们向向量数据库提出问题时,数据库并没有很好的理解问题的语义,所以返回的结果不如预期。要解决这个问题,我们可以通过过滤元数据的方式来实现精准搜索,当前很多向量数据库都支持对
元数据(metadata)的操作:metadata为每个嵌入的块(embedded chunk)提供上下文。
question_chinese = "他们在第二讲中对Figure说了些什么?" Copy to clipboardErrorCopied
现在,我们以手动的方式来解决这个问题,我们会指定一个元数据过滤器filter
docs_chinese = vectordb_chinese.similarity_search(
question_chinese,
k=3,filter={"source":"docs/matplotlib/第二回:艺术画笔见乾坤.pdf"}
- 使用自查询检索器(LLM辅助检索) 我们手动设置了过滤参数 filter 来过滤指定文档。但这种方式不够智能,需要人工指定过滤条件。如何自动从用户问题中提取过滤信息呢? LangChain提供了SelfQueryRetriever模块,它可以通过语言模型从问题语句中分析出:
- 向量搜索的查询字符串(search term)
- 过滤文档的元数据条件(Filter)
结合各种技术
值得注意的是,vetordb 并不是唯一一种检索文档的工具。LangChain 还提供了其他检索文档的方式,例如:TF-IDF 或 SVM。
回答output(问答链)
评估
Debug
import langchain
langchain.debug = True
#重新运行与上面相同的示例,可以看到它开始打印出更多的信息
qa.run(examples[0]["query"])
[chain/start] [1:chain:RetrievalQA] Entering Chain run with input:
{
"query": "高清电视机怎么进行护理?"
}
[chain/start] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain] Entering Chain run with input:
[inputs]
[chain/start] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain > 4:chain:LLMChain] Entering Chain run with input:
{
"question": "高清电视机怎么进行护理?",
"context": "product_name: 高清电视机\ndescription: 规格:\n尺寸:50''。\n\n为什么我们热爱它:\n我们的高清电视机拥有出色的画质和强大的音效,带来沉浸式的观看体验。\n\n材质与护理:\n使用干布清洁。\n\n构造:\n由塑料、金属和电子元件制成。\n\n其他特性:\n支持网络连接,可以在线观看视频。\n配备遥控器。\n在韩国制造。\n\n有问题?请随时联系我们的客户服务团队,他们会解答您的所有问题。<<<<>>>>>product_name: 空气净化器\ndescription: 规格:\n尺寸:15'' x 15'' x 20''。\n\n为什么我们热爱它:\n我们的空气净化器采用了先进的HEPA过滤技术,能有效去除空气中的微粒和异味,为您提供清新的室内环境。\n\n材质与护理:\n清洁时使用干布擦拭。\n\n构造:\n由塑料和电子元件制成。\n\n其他特性:\n三档风速,附带定时功能。\n在德国制造。\n\n有问题?请随时联系我们的客户服务团队,他们会解答您的所有问题。<<<<>>>>>product_name: 宠物自动喂食器\ndescription: 规格:\n尺寸:14'' x 9'' x 15''。\n\n为什么我们热爱它:\n我们的宠物自动喂食器可以定时定量投放食物,让您无论在家或外出都能确保宠物的饮食。\n\n材质与护理:\n可用湿布清洁。\n\n构造:\n由塑料和电子元件制成。\n\n其他特性:\n配备LCD屏幕,操作简单。\n可以设置多次投食。\n在美国制造。\n\n有问题?请随时联系我们的客户服务团队,他们会解答您的所有问题。<<<<>>>>>product_name: 玻璃保护膜\ndescription: 规格:\n适用于各种尺寸的手机屏幕。\n\n为什么我们热爱它:\n我们的玻璃保护膜可以有效防止手机屏幕刮伤和破裂,而且不影响触控的灵敏度。\n\n材质与护理:\n使用干布擦拭。\n\n构造:\n由高强度的玻璃材料制成。\n\n其他特性:\n安装简单,适合自行安装。\n在日本制造。\n\n有问题?请随时联系我们的客户服务团队,他们会解答您的所有问题。"
}
[llm/start] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain > 4:chain:LLMChain > 5:llm:ChatOpenAI] Entering LLM run with input:
{
"prompts": [
"System: Use the following pieces of context to answer the users question. \nIf you don't know the answer, just say that you don't know, don't try to make up an answer.\n----------------\nproduct_name: 高清电视机\ndescription: 规格:\n尺寸:50''。\n\n为什么我们热爱它:\n我们的高清电视机拥有出色的画质和强大的音效,带来沉浸式的观看体验。\n\n材质与护理:\n使用干布清洁。\n\n构造:\n由塑料、金属和电子元件制成。\n\n其他特性:\n支持网络连接,可以在线观看视频。\n配备遥控器。\n在韩国制造。\n\n有问题?请随时联系我们的客户服务团队,他们会解答您的所有问题。<<<<>>>>>product_name: 空气净化器\ndescription: 规格:\n尺寸:15'' x 15'' x 20''。\n\n为什么我们热爱它:\n我们的空气净化器采用了先进的HEPA过滤技术,能有效去除空气中的微粒和异味,为您提供清新的室内环境。\n\n材质与护理:\n清洁时使用干布擦拭。\n\n构造:\n由塑料和电子元件制成。\n\n其他特性:\n三档风速,附带定时功能。\n在德国制造。\n\n有问题?请随时联系我们的客户服务团队,他们会解答您的所有问题。<<<<>>>>>product_name: 宠物自动喂食器\ndescription: 规格:\n尺寸:14'' x 9'' x 15''。\n\n为什么我们热爱它:\n我们的宠物自动喂食器可以定时定量投放食物,让您无论在家或外出都能确保宠物的饮食。\n\n材质与护理:\n可用湿布清洁。\n\n构造:\n由塑料和电子元件制成。\n\n其他特性:\n配备LCD屏幕,操作简单。\n可以设置多次投食。\n在美国制造。\n\n有问题?请随时联系我们的客户服务团队,他们会解答您的所有问题。<<<<>>>>>product_name: 玻璃保护膜\ndescription: 规格:\n适用于各种尺寸的手机屏幕。\n\n为什么我们热爱它:\n我们的玻璃保护膜可以有效防止手机屏幕刮伤和破裂,而且不影响触控的灵敏度。\n\n材质与护理:\n使用干布擦拭。\n\n构造:\n由高强度的玻璃材料制成。\n\n其他特性:\n安装简单,适合自行安装。\n在日本制造。\n\n有问题?请随时联系我们的客户服务团队,他们会解答您的所有问题。\nHuman: 高清电视机怎么进行护理?"
]
}
[llm/end] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain > 4:chain:LLMChain > 5:llm:ChatOpenAI] [2.86s] Exiting LLM run with output:
{
"generations": [
[
{
"text": "高清电视机的护理非常简单。您只需要使用干布清洁即可。避免使用湿布或化学清洁剂,以免损坏电视机的表面。",
"generation_info": {
"finish_reason": "stop"
},
"message": {
"lc": 1,
"type": "constructor",
"id": [
"langchain",
"schema",
"messages",
"AIMessage"
],
"kwargs": {
"content": "高清电视机的护理非常简单。您只需要使用干布清洁即可。避免使用湿布或化学清洁剂,以免损坏电视机的表面。",
"additional_kwargs": {}
}
}
}
]
],
"llm_output": {
"token_usage": {
"prompt_tokens": 823,
"completion_tokens": 58,
"total_tokens": 881
},
"model_name": "gpt-3.5-turbo"
},
"run": null
}
[chain/end] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain > 4:chain:LLMChain] [2.86s] Exiting Chain run with output:
{
"text": "高清电视机的护理非常简单。您只需要使用干布清洁即可。避免使用湿布或化学清洁剂,以免损坏电视机的表面。"
}
[chain/end] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain] [2.87s] Exiting Chain run with output:
{
"output_text": "高清电视机的护理非常简单。您只需要使用干布清洁即可。避免使用湿布或化学清洁剂,以免损坏电视机的表面。"
}
[chain/end] [1:chain:RetrievalQA] [3.26s] Exiting Chain run with output:
{
"result": "高清电视机的护理非常简单。您只需要使用干布清洁即可。避免使用湿布或化学清洁剂,以免损坏电视机的表面。"
}
'高清电视机的护理非常简单。您只需要使用干布清洁即可。避免使用湿布或化学清洁剂,以免损坏电视机的表面。'
人工评估
学习资料
LangChain官方文档:https://python.langchain.com/docs/introduction/
视频学习: https://space.bilibili.com/256673804/lists/2101097?type=season