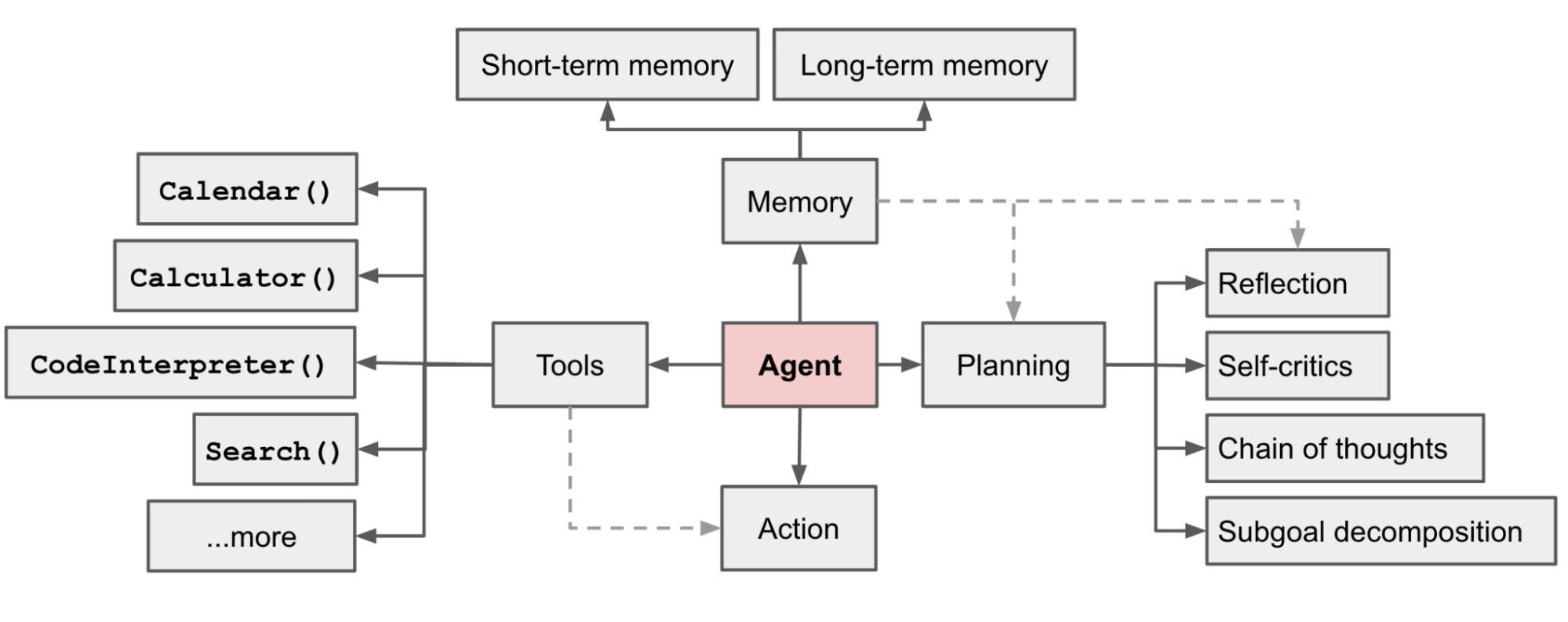
Agent

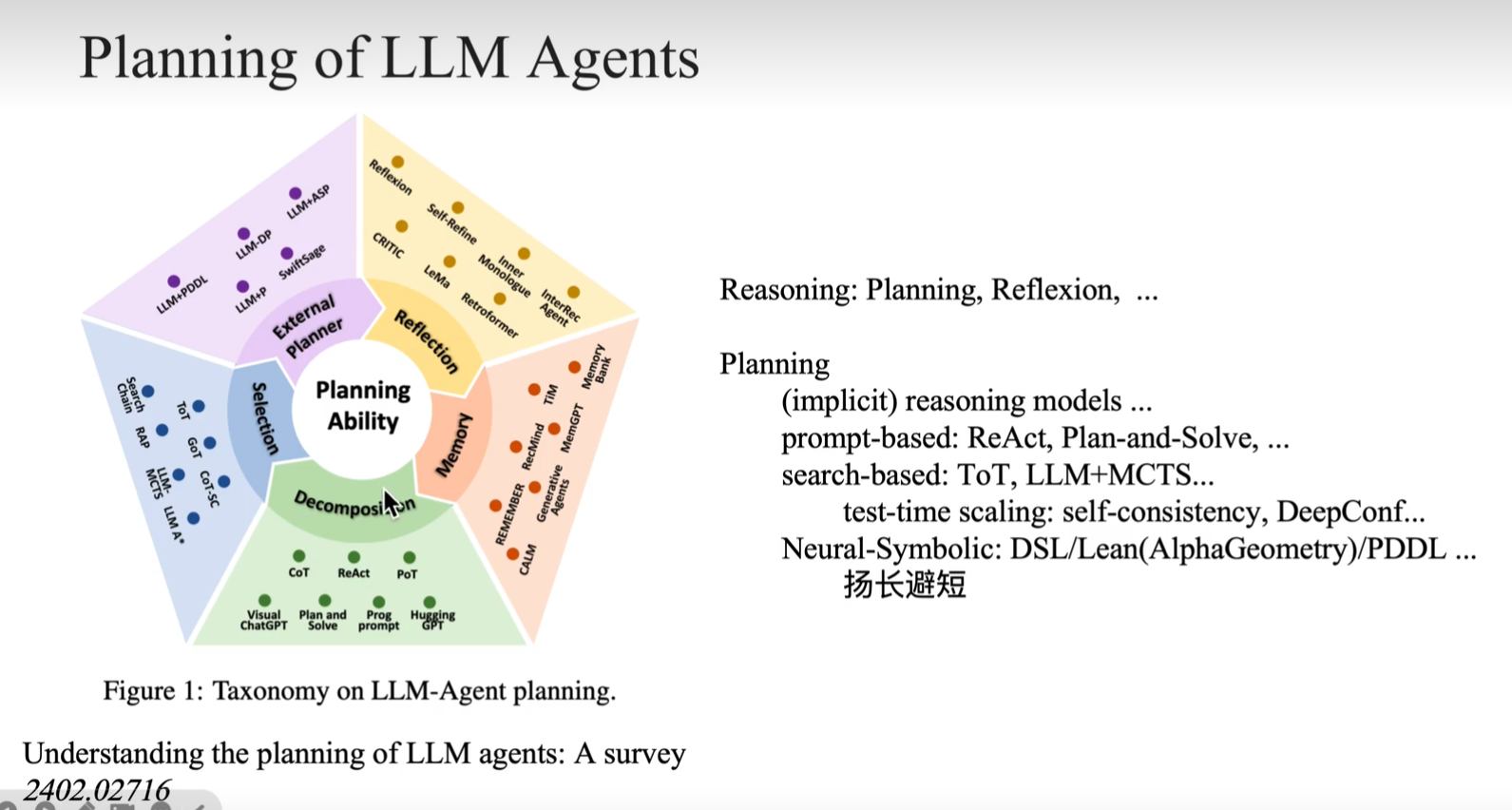
Planning
概述
https://arxiv.org/abs/2402.02716
为什么需要plan:
-
原理解析: 大模型本质上是“自回归”模型,也就是根据前面的词预测下一个词(Token预测)。当任务步骤非常长时(比如超过 10 步),它极容易“忘掉”最初始的条件,或者在中间某一步产生一点点幻觉,导致后面的步骤全部如同“建立在沙丘上的城堡”一样崩塌。
-
为什么吗会这样呢?因为没有一个实时的“全局变量”来存储每一步走完后的世界状态。写到第 4 步时,它的注意力机制(Attention)没能成功抓取到“第 2 步已经占用了 b5”这个隐式信息。
工程演进技术路线:
1、(implicit) reasoning models (隐式推理模型)
- 概念解析:这是指大模型依靠自身海量参数和预训练数据,通过“预测下一个 Token”自然展现出来的推理能力。比如你问一个简单逻辑题,它直接给你答案。
- 工程视角:这是一种“黑盒”推理。它的上限取决于模型本身的底座能力。对于开发者来说,这种方式不可控、不可解释、容易产生幻觉。在严肃的业务场景中,我们很少直接依赖纯粹的隐式推理来解决复杂问题。
2、prompt-based: ReAct, Plan-and-Solve... (基于提示词的方法)
- 概念解析:既然模型内在推理不可控,我们就通过**提示词工程(Prompt Engineering)**强迫模型把思考过程“显式”地写出来。
- ReAct (Reason + Act):要求模型在执行任何工具之前,必须先输出一段
Thought(思考过程),然后再输出Action(动作)。 - Plan-and-Solve:要求模型先输出一个分步骤的计划(Plan),然后再逐条执行(Solve)。
- ReAct (Reason + Act):要求模型在执行任何工具之前,必须先输出一段
- 工程视角:这是目前性价比最高、应用最广泛的 Agent 开发模式。它的本质是在系统层面上做了一层拦截,强制模型遵循特定的思考模板。你只需要几段写得很好的 Prompt 加上基础的代码解析逻辑,就能构建一个基础的智能体。
3、search-based: ToT, LLM+MCTS... (基于搜索的方法)
- 概念解析:当问题复杂到一步步想也会出错时,就需要引入经典的计算机科学算法了。把大模型的每一次输出看作图或树上的一个节点,让模型去探索多条路径,并在路径中进行评估和回溯。
- ToT (Tree of Thoughts, 思维树):让模型生成多个不同的思考分支,并对分支的靠谱程度打分,保留高分分支继续往下走。
- LLM + MCTS (蒙特卡洛树搜索):借鉴 AlphaGo 的思路,在未知的解空间中进行采样和模拟,寻找最优路径。
4、Neural-Symbolic: DSL/Lean(AlphaGeometry)/PDDL... (神经符号学方法)
- 概念解析:这就是“扬长避短”的终极体现。
- Neural (神经):大模型擅长意图理解、自然语言交互、模糊匹配(长处),但不擅长精确计算、严密的数理逻辑证明(短处)。
- Symbolic (符号):传统的计算引擎、规则引擎、求解器(如计算器、数据库查询引擎)擅长100%精确的逻辑执行(长处),但听不懂自然语言(短处)。
- 工程落地:让大模型充当“翻译官”和“调度员”。
- DSL (领域特定语言):让 LLM 把用户的自然语言需求,翻译成系统能懂的 JSON、SQL 或者是你们自己定义的 DSL。
- PDDL (规划领域定义语言):在非常复杂的运筹规划场景(比如物流调度),让大模型把当前状态翻译成 PDDL 代码,然后交给专业的求解器去算出最优解。
高效workflow说明
https://github.com/ginobefun/agentic-design-patterns-cn
https://github.com/FareedKhan-dev/all-agentic-architectures
https://blog.csdn.net/2401_85390073/article/details/146457416
个人代码实践:
https://colab.research.google.com/drive/1MRBQPOQu9sw3lS3TU9tpjASWwMfAlIJJ#scrollTo=WzZ0bwQCQZdr
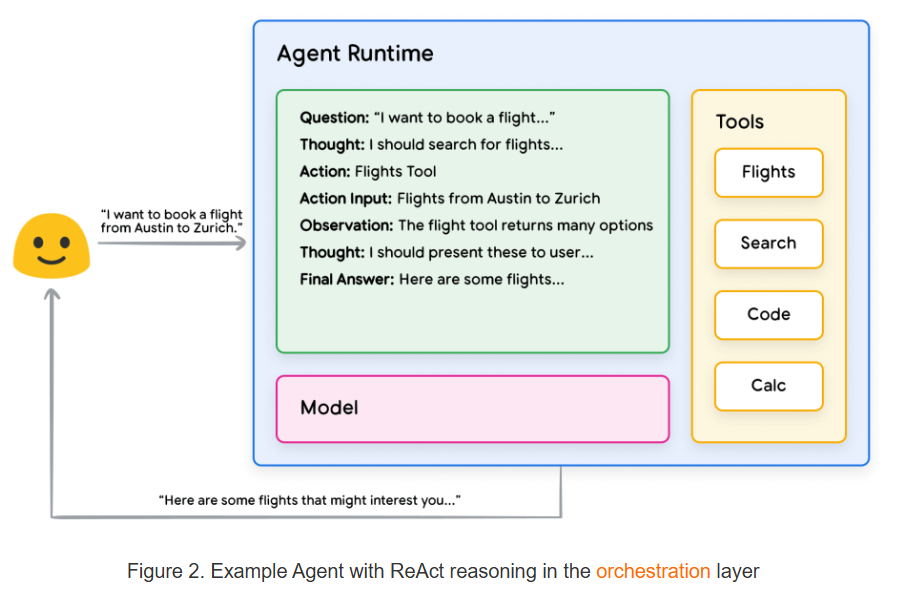
ReAct
原理
ReAct = Reason + Act(推理 + 行动) = think -> act -> observe 循环
是一种 agent 将推理步骤与行动交错进行的模式。agent 不会事先规划好全部步骤,而是对「下一步」生成思考,再采取行动(如调用工具),观察结果,并用新信息生成下一轮思考与行动,形成动态、可适应的循环。

适合场景
主题词:搜索(外部信息补充)、交互
-
多跳问答: 需要按顺序查找多条信息的问题(例如「生产 iPhone 的公司 CEO 是谁?」)。
-
网页导航与研究: 先搜索起点,阅读结果,再基于新信息决定下一轮查询。
-
交互式工作流: 环境动态、无法事先知道完整求解路径的任务。
-
需要调用外部实时数据的场景 LLM 的知识有截止日期。如果用户询问“今天北京的天气如何”或“某公司的最新财报”,模型必须通过 ReAct 模式先决定去调用“天气 API”或“搜索工具”,拿到结果后再回答。
-
需要与企业内部私有数据交互 (RAG 增强) 当用户提出的问题涉及数据库、本地文档或特定的业务逻辑时,ReAct 可以驱动 Agent 在向量数据库(Vector DB)和 SQL 数据库之间切换,灵活获取上下文。
代码
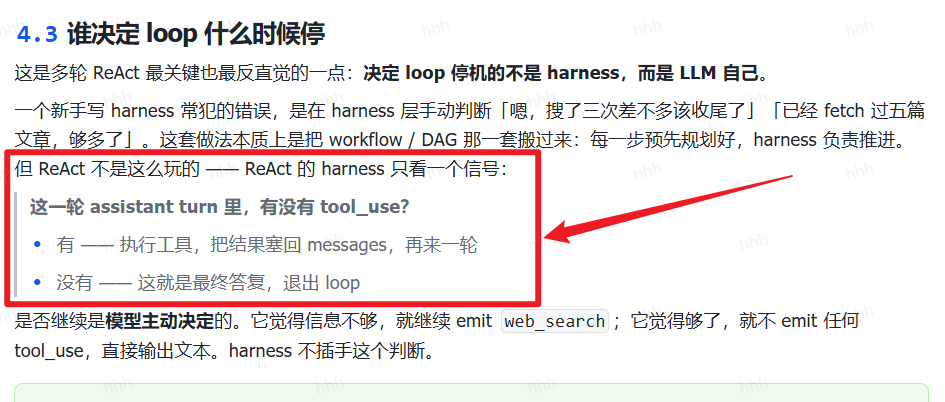
react中的agent loop什么时候停
[Harness 101:从 ReAct Loop 讲起]
Reflection : Verification-and-Refinement
基本概念
https://github.com/lyang36/IMO25.git
https://arxiv.org/pdf/2507.15855
改造的基于 genai sdk (流式)代码:https://github.com/chunhuizhang/prompts_for_academic/blob/main/math/scripts/imo-gemini-sdk.py
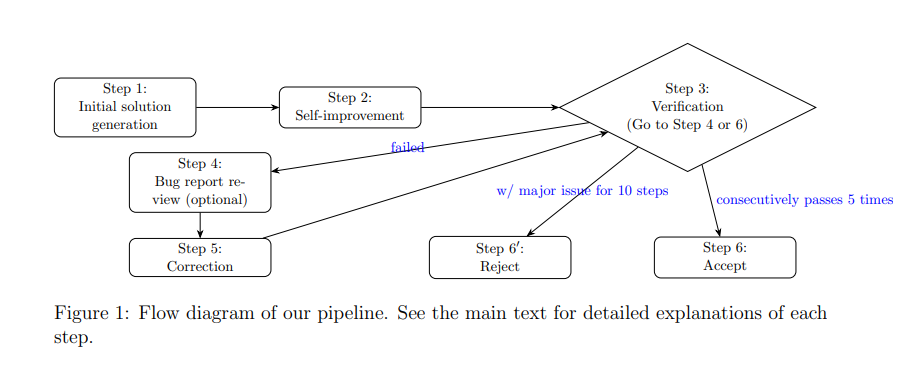

代码
-
定义数据结构(不同节点的输出pydantic)
-
定义节点和边
-
定义state,并增加节点和边
-
编译图
-
构建模型,流式获取结果
为什么需要它?
LLM 存在一些天然缺陷,通过该策略可以有效缓解:
-
减少幻觉 (Hallucination):模型在第一次尝试时可能会编造事实,但在“检查”阶段往往能识别出这些不合理之处。
-
提升逻辑推理能力:在处理复杂的数学题、编程或长逻辑链条时,模型很难“一步到位”。通过拆解步骤并反复打磨,成功率会大幅提升。
-
指令遵循度:确保最终结果完全符合用户设定的格式或特定规则。(例如json输出)
适用场景 / 应用
-
代码生成: 初稿代码可能有 bug、效率低或缺少注释。Reflection 让智能体充当自己的代码评审,先修正再输出。
-
复杂摘要: 面对高密度文档,一次总结常会漏细节。反思步骤可提升摘要的完整性和准确性。
-
创作与内容生产: 邮件、博客、故事等初稿通常可优化。Reflection 有助于改进语气、清晰度与表达力度。
优势与局限
-
优势:
- 质量提升: 能直接发现并纠正问题,输出更准确、更稳健、推理更完整。
- 开销较低: 概念简单,可用单个 LLM 实现,不依赖复杂外部系统。
-
局限:
- 自我偏差: 智能体仍受自身知识和偏见限制;它能修复“看得见”的问题,但无法凭空补齐“本来就不知道”的知识。
- 时延与成本增加: 至少需要两次 LLM 调用(生成 + 批评/修订),比单次生成更慢、更贵。
常见的变体包括:
-
Self-Correction (自我修正):同一个模型扮演“创作者”和“评论家”。
-
Multi-Agent Debate (多智能体辩论):由模型 A 生成,模型 B 负责找茬(验证),模型 A 根据反馈修改。
-
External Tool Verification (外部工具验证):
- 生成代码后,直接在 Python 环境中运行,报错了就返回给模型修改。
- 生成数学证明后,调用计算器或 Lean 等数学证明引擎进行核对。
plan
plan-and-Executor
- 定义
Planning 架构指 agent 在开始执行前就将复杂目标显式分解为详细子任务序列。规划阶段的产出是具体、逐步的计划,随后由 agent 按步骤执行直至得到解。
-
高层工作流
-
接收目标: 获得复杂任务。
-
规划: 专用「Planner」分析目标,生成有序子任务列表,例如:
["查找事实 A", "查找事实 B", "用 A 和 B 计算 C"]。 -
执行: 「Executor」按顺序执行计划中每一步,按需调用工具。
-
综合: 计划全部完成后,最终组件将各步结果合成为连贯的最终答案。
-
适用场景 / 应用
- 多步工作流: 操作顺序已知且关键的任务,如需拉取数据、处理再汇总的报告生成。
- 项目管理助手: 将「上线新功能」等大目标拆给不同团队。
- 教学辅导: 从基础到应用,为学生制定某概念的学习计划。
- 代码
Planner: 基于 LLM 的节点,接收用户请求并输出结构化计划。Executor: 接收计划,用工具执行下一步并记录结果。Synthesizer: 最终基于 LLM 的节点,汇总所有收集结果并生成最终答案。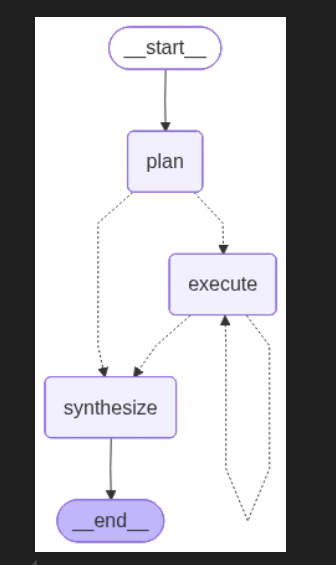
Planner → Executor → Verifier (PEV)
class VerificationResult(BaseModel):
"""Schema for the Verifier's output."""
is_successful: bool = Field(description="True if the tool execution was successful and the data is valid.")
reasoning: str = Field(description="Reasoning for the verification decision.")
class PEVState(TypedDict):
user_request: str
plan: Optional[List[str]]
last_tool_result: Optional[str]
intermediate_steps: List[str]
final_answer: Optional[str]
retries: int # count how many times we’ve replanned
from langchain_core.exceptions import OutputParserException
class Plan(BaseModel):
steps: List[str] = Field(
description="List of queries (max 5).",
max_items=5
)
def pev_planner_node(state: PEVState):
retries = state.get("retries", 0)
if retries > 3: # stop after 3 replans
console.print("--- (PEV) PLANNER: Retry limit reached. Stopping. ---")
return {
"plan": [],
"final_answer": "Error: Unable to complete task after multiple retries."
}
console.print(f"--- (PEV) PLANNER: Creating/revising plan (retry {retries})... ---")
planner_llm = llm.with_structured_output(Plan, strict=True) # ✅ strict schema
past_context = "\n".join(state["intermediate_steps"])
base_prompt = f"""
You are a planning agent.
Create a plan to answer: '{state['user_request']}'.
Use the 'flaky_web_search' tool.
Rules:
- Return ONLY valid JSON in this exact format: {{ "steps": ["query1", "query2"] }}
- Maximum 5 steps.
- Do NOT repeat failed queries or endless variations.
- Do NOT output explanations, only JSON.
Previous attempts and results:
{past_context}
"""
# ✅ retry wrapper for bad JSON
for attempt in range(2):
try:
plan = planner_llm.invoke(base_prompt)
return {"plan": plan.steps, "retries": retries + 1}
except OutputParserException as e:
console.print(f"[red]Planner parsing failed (attempt {attempt+1}): {e}[/red]")
base_prompt = f"Return ONLY valid JSON with {{'steps': ['...']}}. {base_prompt}"
# ultimate fallback to avoid crashing
return {"plan": ["Apple R&D spend last fiscal year"], "retries": retries + 1}
def pev_executor_node(state: PEVState):
if not state.get("plan"): # ✅ guard against empty plan
console.print("--- (PEV) EXECUTOR: No steps left, skipping execution. ---")
return {}
console.print("--- (PEV) EXECUTOR: Running next step... ---")
next_step = state["plan"][0]
result = flaky_web_search(next_step)
return {"plan": state["plan"][1:], "last_tool_result": result}
def verifier_node(state: PEVState):
console.print("--- VERIFIER: Checking last tool result... ---")
verifier_llm = llm.with_structured_output(VerificationResult)
prompt = f"Verify if the following tool output is a successful result or an error message. The task was '{state['user_request']}'.\n\nTool Output: '{state['last_tool_result']}'"
verification = verifier_llm.invoke(prompt)
console.print(f"--- VERIFIER: Judgment is '{'Success' if verification.is_successful else 'Failure'}' ---")
if verification.is_successful:
# If successful, add the valid result to our list of good steps
return {"intermediate_steps": state["intermediate_steps"] + [state['last_tool_result']]}
else:
# If failed, add the failure reason and trigger re-planning by clearing the plan
return {"plan": [], "intermediate_steps": state["intermediate_steps"] + [f"Verification Failed: {state['last_tool_result']}"]}
pev_synthesizer_node = basic_synthesizer_node # We can reuse the same synthesizer
def pev_router(state: PEVState):
# ✅ If we already have a final answer (e.g. retry limit reached), stop
if state.get("final_answer"):
console.print("--- ROUTER: Final answer available. Moving to synthesizer. ---")
return "synthesize"
if not state["plan"]:
# Check if plan is empty because of verification failure
if state["intermediate_steps"] and "Verification Failed" in state["intermediate_steps"][-1]:
console.print("--- ROUTER: Verification failed. Re-planning... ---")
return "plan"
else:
console.print("--- ROUTER: Plan complete. Moving to synthesizer. ---")
return "synthesize"
else:
console.print("--- ROUTER: Plan has more steps. Continuing execution. ---")
return "execute"
# Build the PEV graph
pev_graph_builder = StateGraph(PEVState)
pev_graph_builder.add_node("plan", pev_planner_node)
pev_graph_builder.add_node("execute", pev_executor_node)
pev_graph_builder.add_node("verify", verifier_node)
pev_graph_builder.add_node("synthesize", pev_synthesizer_node)
pev_graph_builder.set_entry_point("plan")
pev_graph_builder.add_edge("plan", "execute")
pev_graph_builder.add_edge("execute", "verify")
pev_graph_builder.add_conditional_edges("verify", pev_router)
pev_graph_builder.add_edge("synthesize", END)
pev_agent_app = pev_graph_builder.compile()
print("Planner-Executor-Verifier (PEV) agent compiled successfully.")
from IPython.display import Image, display
display(Image(pev_agent_app.get_graph().draw_mermaid_png()))
变体 Dynamic plan-and-solve
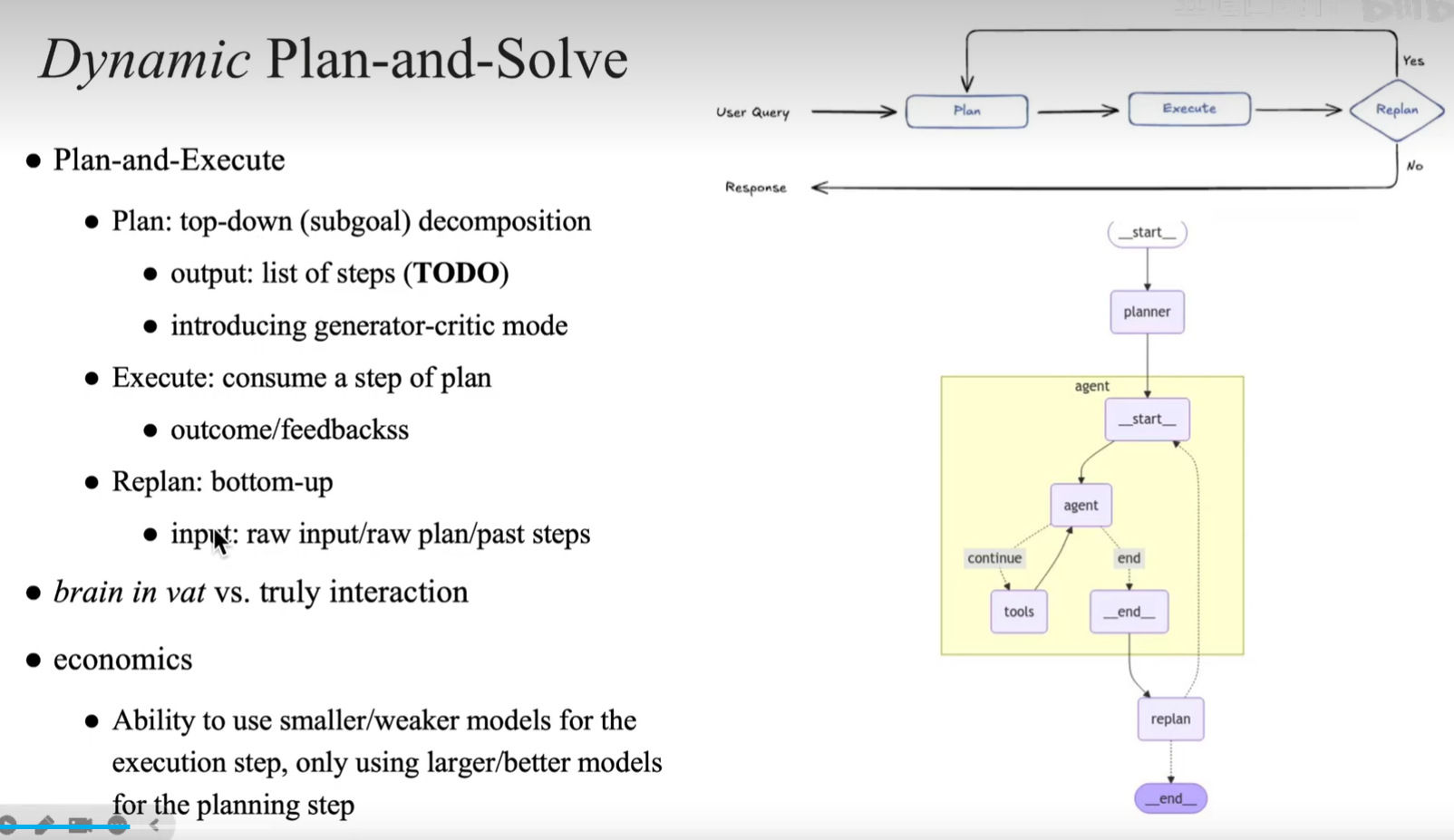
https://arxiv.org/pdf/2305.04091
- Plan (自顶向下的目标分解):
- 面对复杂的 User Query,系统不会立刻去使用工具,而是先进行全局拆解,输出一个具体的步骤列表(TODO list)。
- Generator-critic mode (生成-评估模式): 这里提到一种高阶玩法,即在规划阶段,系统不仅“生成”计划,还会引入一个“评估者(Critic)”角色来审查计划的合理性,确保计划可行后再下发。
- Execute (执行):
- 执行器每次只专注“消费” TODO 列表中的一个子任务。
- 执行完成后,收集当前步骤的真实结果和反馈(outcome/feedbacks)。
- Replan (自底向上的动态重规划):
- 这是“Dynamic(动态)”的核心所在。执行完一步后,系统会将“原始问题”、“当前计划”以及“刚才执行的结果”放在一起审视。
- 如果在执行中发现了新线索,或者某条路走不通,系统会自底向上地修改或生成新的 TODO 列表,而不是死板地执行旧计划。
优势:
Brain in a vat vs. truly interaction (缸中之脑 vs. 真实交互):
- 仅靠模型内部生成的静态计划就像“缸中之脑”,脱离实际。这种架构通过“执行 -> 反馈 -> 重规划”的闭环,让 Agent 真正与外部环境发生了交互纠偏。
Economics (经济性 - 架构落地的巨大优势):
-
模型解耦: “规划(Planning)”和“重规划(Replanning)”对逻辑推理要求极高,通常需要调用参数量最大、最聪明的大模型。
-
但“执行(Execute)”往往只是调用特定 API、提取网页文本等具象任务,这时可以切换调度更小、更便宜、速度更快的模型(例如较小的开源模型)。这种“大模型带小模型”的策略在工程实践中能大幅降低 Token 成本并提升响应速度。
代码:
COT
- Chain of thought(COT):
- 模型被要求“think step by step”利用更多的时间进行计算,将艰难的任务分解 成更小,更简单的步骤。CoT将大型任务转化为多个可管理的任务,并对模型的思维过程进行了阐 释
TOT
-
Tree of Thoughts(TOT):
-
进一步扩展CoT,在每一步都探索多种推理的可能性。它首先将问题分解为多 个思考步骤,并在每个步骤中生成多个思考,从而创造一个树形结构。搜索过程可以是BFS(广度优 先搜索)或DFS(深度优先搜索),每个状态由分类器(通过一个prompt)或少数服从多数的投 票原则来决定。
-
任务分解可通过以下几种方式实现: 1. a. 给LLM一个简单的提示词“Steps for XYZ.\n1.”,“What are the subgoals for achieving XYZ?”; 1. b. 使用针对具体任务的指令,例如对一个写小说的任务先给出“Write a story outline.”指令; 1. c. 使用者直接输入;
-
本质是树结构的遍历过程,把所有解决方案遍历一遍
GOT
- Graph of Thoughts(GOT):
- 同时支持多链、树形以及任意图形结构的Prompt方案,支持各种基于图形的 思考转换,如聚合、回溯、循环等,这在CoT和ToT中是不可表达的。将复杂问题建模为操作图 (Graph of Operations,GoO),以LLM作为引擎自动执行,从而提供解决复杂问题的能力。某种程 度上,GoT囊括了单线条的CoT和多分枝的ToT。
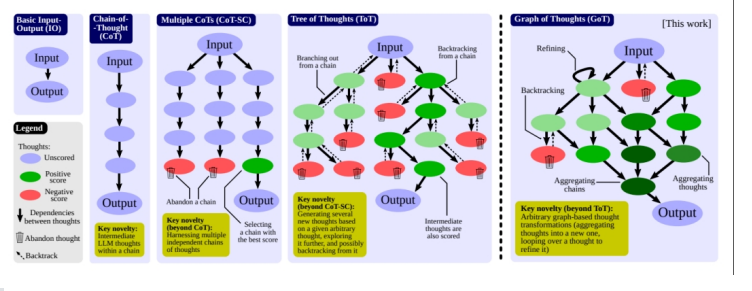
Mental-Model-in-the-Loop
Storm
multi-agents
https://github.com/datawhalechina/hugging-multi-agent
适用场景 / 应用
-
复杂报告: 需金融、科研等多领域专长的详细报告。
-
软件开发流水线: 模拟开发、评审、测试、项目经理等角色。
-
创意头脑风暴: 不同「性格」的 agent(乐观、谨慎、天马行空)可产生更多样想法。
优势与局限
-
优势:
-
专业化与深度: 每个 agent 可针对人设与工具微调,领域内质量更高。
-
模块化与可扩展: 增删、升级单个 agent 不必重做整个系统。
-
并行: 多 agent 可同时处理子任务,可能缩短总耗时。
-
-
局限:
-
协调成本: 管理 agent 间通信与工作流增加设计复杂度。
-
成本与延迟: 多轮 LLM 调用通常比单 agent 更贵、更慢。
-
需要考虑的因素
不同agent之间的通信、是否共享context和memory,组织合作方式
-
muti-agent的不同架构 https://zhuanlan.zhihu.com/p/696433906
-
agent间的通信方式
黑板模式
黑板系统(Blackboard System):一种强大且灵活的多专家智能体协作模式。该架构借鉴人类专家围在一块物理黑板前协作解决复杂问题的思路。
与僵硬、预先固定的智能体交接顺序不同,黑板系统具有中央共享数据存储(「Blackboard」),各智能体可读取问题当前状态并写入自己的贡献。动态的 Controller(控制器) 观察黑板,并根据推进解所需决定下一步激活哪位专家,从而形成机会式、涌现式的工作流。
- 适用场景 / 应用
- 复杂、结构不良的问题: 适合解路径事先未知、需要涌现式、机会式策略的问题(如复杂诊断、科学发现)。
- 多模态系统: 协调处理不同数据类型(文本、图像、代码)的智能体,均可将发现发布到共享黑板。
- 动态意义建构: 需要从许多分散、异步来源综合信息的场景。
- 优势与局限 优势: 灵活性与适应性: 工作流非硬编码,随问题涌现,系统高度自适应。 模块化: 增删专家智能体通常无需重构整个系统。 局限: 控制器复杂度: 系统整体智能很大程度上取决于控制器的成熟度;幼稚的控制器可能导致低效或循环行为。 调试难度: 非线性、涌现式工作流有时比简单顺序流程更难追踪与调试。
Meta-controller(可以称为路由agent)
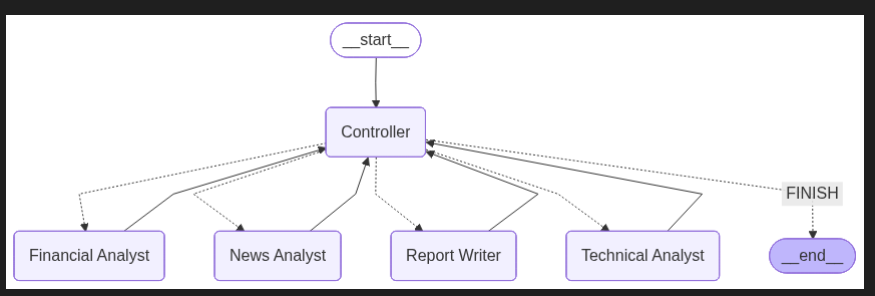
元控制器(或称路由器)是多智能体系统中的监督智能体,负责分析到达的任务并将其分派给合适的专家子智能体或工作流。它作为智能路由层,决定当前任务最适合哪种工具或专家。
所有的节点从controller节点开始,controller节点结束
-
高层工作流
-
接收输入: 系统收到用户请求。
-
元控制器分析: 元控制器审视请求的意图、复杂度与内容。
-
分派专家: 根据分析,从预定义池中选择最合适的专家智能体(如「Researcher」「Coder」「Chatbot」)。
-
执行任务: 被选中的专家执行任务并生成结果。
-
返回结果: 将专家结果返回用户;在更复杂流程中,控制权可能回到元控制器以进行后续步骤或监控。
-
适用场景 / 应用
-
多服务 AI 平台: 单一入口提供文档分析、数据可视化、创意写作等多样服务。
-
自适应个人助理: 在日历、网页搜索、智能家居控制等模式或工具间切换。
-
企业工作流: 根据工单内容将客服请求路由到技术、账单、销售等部门。
-
优势与局限
- 优势:
- 灵活与模块化: 新增专家并更新路由逻辑即可扩展能力。
- 性能: 可使用高度优化的专家智能体,而非样样平庸的「万金油」模型。
- 局限:
- 控制器单点风险: 整体质量高度依赖路由是否正确;错误路由会导致次优或错误结果。
- 潜在延迟增加: 相比直接调用单一智能体,路由步骤可能带来少量额外时延。
- 应用
- 可以和黑板模式相结合,或者单开一个
并行探索 + 集成决策
和黑板与meta的区别:前者是智能路由到一个适用的agent进行操作,后者是真实并行,再汇总结果
Parallel Exploration + Ensemble Decision-Making
-
定义
-
并行探索 + 集成决策 指:同一问题由多个独立智能体或推理路径同时处理,个体输出再经聚合(常由单独智能体通过投票、共识或综合)得到更稳健的最终结论。
-
高层工作流
-
扇出(并行探索): 用户查询被分发给 N 个独立专家智能体;通常通过不同指令、人设或工具鼓励分析路径多样化。
-
独立处理: 各智能体隔离工作,各自生成完整分析、结论或答案。
-
扇入(聚合): 收集全部 N 个智能体的输出。
-
综合(集成决策): 最终「聚合器」或「评判」智能体接收所有观点,分析异同、权衡冲突证据,形成全面答案。
-
适用场景 / 应用
-
困难推理问答: 复杂、模糊的问题,单一路径易忽略细微差别(例如「2008 年金融危机主因是什么?」)。
-
事实核查与验证: 多智能体从不同来源检索并核对事实,可显著降低幻觉。
-
高风险决策支持: 医疗、金融等领域,在给出建议前用不同 AI 人设获取「第二意见」(或第三、第四意见)。
-
优势与局限
-
优势: 提升可靠性与准确性: 平滑单一智能体的随机误差或偏差,最终答案更可能正确、全面。 降低幻觉: 若一个智能体幻觉事实,其他往往不会,聚合器易发现离群值。
-
局限: 成本很高: 智能体数量会成倍增加 LLM 调用(另加最终聚合调用),是最昂贵的架构之一。 延迟增加: 必须等待全部并行路径完成后才能开始最终综合。
Cellular automata(元细胞机)
探索一种截然不同的智能体架构:元胞自动机 与 基于网格的智能体系统。该模式受自然复杂系统(如康威生命游戏)启发,将范式从少数复杂、中心化的智能体,转向大量简单、去中心化的网格智能体。
在此模型中,环境本身即智能体。网格中每个单元是带自身状态、并根据邻域用简单规则同步更新的小智能体;无中央控制器或复杂寻路。智能的全局行为由这些简单局部规则的重复、同步应用 涌现。系统成为通过类波传播信息来求解问题的「计算织物」。
- 定义
基于网格的智能体系统 是一种架构:大量简单智能体(或「单元」)排列在空间网格中;每个智能体有状态,并仅根据直接邻域的状态、按规则集同步更新。复杂的高层模式与问题求解能力从这些局部交互中涌现。
-
高层工作流
-
网格初始化: 创建单元智能体网格,各单元初始化类型(如障碍、空地)与状态(如数值)。
-
设定边界条件: 将一个或多个单元设为特殊状态以启动计算(例如目标单元值设为 0)。
-
同步步进: 系统按「步」推进;每一步中,所有单元同时根据当前邻域计算下一状态。
-
涌现: 随步进推进,信息如波在网格上传播,可形成梯度、路径等结构。
-
状态稳定: 运行直至网格不再变化,表示计算完成。
-
读出: 问题的解直接从网格最终状态读出(例如沿计算出的梯度行走)。
-
适用场景
空间推理与物流: 动态环境中的最优路径(如本仓库示例)。
复杂系统仿真: 森林火灾、疾病传播、城市增长等涌现现象建模。
并行计算: 某些算法可映射为元胞自动机,在高度并行硬件(如 GPU)上执行。
- 优势与局限
- 优势: 高并行性: 逻辑天然并行,在合适硬件上极快。 适应性: 环境变化(如新障碍)可通过重新传播波动态响应。 涌现复杂性: 用惊人简单的规则求解很复杂的问题。
- 局限: 规则设计难: 设计局部规则以得到期望全局行为可能反直觉且困难。 可解释性弱: 难以向单个单元追问「为何」处于某状态;推理分布在整个系统。
RLHF : 强化学习 + agent
外部模块 External Module
概念:LLM 本质上是概率模型,逻辑并不严密。这种方法是把复杂的逻辑规划任务“外包”给传统的、基于规则的确定性规划器。
代表技术:LLM+PDDL(规划领域定义语言)。根据所引入的规划器,这些方法可以分为符号规划器和神经规划器。
工程视角:LLM 负责理解自然语言并将其翻译成领域特定语言(DSL),然后由专门的求解器进行运算,最后 LLM 再将结果翻译回人类语言。
-
符号规划器段:符号规划器在自动化规划领域已经使用了数十年
- 基于PDDL等符号形式化模型进行符号推理,以识别从初始状态到目标状态的最优路径。
- LLM+P方法通过引入基于PDDL的符号规划器增强了LLM的规划能力,将问题组织成文本语言提示输入到LLM中,随后使用快速向下规划器进行规划。
- LLM-DP方法在动态交互环境中应用了类似的符号规划器。
- LLM+PDDL方法添加了手动验证步骤以检查生成的PDDL模型中的潜在问题。
- LLM+ASP方法将自然语言描述的问题转化为原子事实,并使用ASP求解器生成计划
-
神经规划器段:神经规划器是通过强化学习或模仿学习技术训练的深度模型,展示了在特定领域内的有效规划能力。
- 例如,DRRN将规划过程建模为马尔可夫决策过程,通过强化学习训练策略网络。
- 决策变压器(DT)通过模仿学习训练变压器模型,克隆人类的决策行为。神经规划器在各自领域内表现出优秀的规划能力,但在面对复杂和不常见的问题时,训练数据不足导致其泛化能力较弱。为此,几种工作探索了将LLM与轻量级神经规划器结合,以进一步增强规划能力。
-
讨论段:利用外部规划器辅助规划的策略中,LLM主要扮演支持角色,其主要功能包括解析文本反馈和提供额外的推理信息,以辅助解决复杂问题。具体而言,LLM在代码生成能力上的增强使其有可能处理更一般的任务。传统符号AI系统的一个显著缺点是构建符号模型的复杂性和对人类专家的依赖,而LLM加速了这一过程,使得符号模型的建立更加快速和优化。符号系统带来的优势包括理论上的完备性、稳定性和可解释性。结合统计AI与LLM的组合有望成为未来人工智能发展的主要趋势。
Hermes- : Plan-then-Act:给 Loop 加一层战略
纯 ReAct 多轮跑复杂问题时有个结构性毛病——模型是「走一步看一步」,没有全局视野。碰到一个需要从五、六个维度拼凑答案的调研题,它会在前两三步里顺手挑几个最显眼的角度查一查,然后就觉得「差不多了」给你收尾。漏掉的那几个维度它自己也不知道漏了。
怎么治?一个粗暴而有效的思路——让它先把 plan 写下来,再去执行。
一个新工具:write_todos
在 Deep Research 的 harness 里,我们给 Agent 加了一件新工具 write_todos。它什么都不做,就是把一个 TODO 列表写到自己的 state 里。System prompt 里那一句就是开关:
<agent>
You're a helpful assistant that can utilize the tools provided to answer questions and help with tasks.
</agent>
<behaviors>
<deep-research activate-when="User explicitly asks to research, investigate, dig into, or study a topic deeply; OR when the user's query involves a complex or unfamiliar topic that would benefit from structured investigation">
- ⚠️ CRITICAL: You MUST follow this workflow when activated. Skipping it is a violation.
- Step 1: Immediately call `web_search` once for initial orientation on the topic (do NOT skip this).
- Step 2: Write a research plan via `write_todos` with 4-8 items that expand both breadth and depth.
- Step 3: Execute each TODO item sequentially or in parallel. After each item, mark it completed.
- Step 4: Dynamically adjust the plan based on new findings.
- ⚠️ Do NOT jump to a final answer before completing the research plan.
</deep-research>
</behaviors>
你知道吗?为什么要用 XML 来写 Prompt 熟悉 Anthropic 提示词工程的朋友们一定都发现了,从 2023 年起,它们家使用的就一直是 XML 风格的 Prompt,2025 年底在 OpenAI GPT 5 的示例中,最外层也从 Markdown 变成了 XML 里封装 Markdown 了。这是因为与 Markdown 比,XML “更容易”让模型找到开闭区间。同时,在拼装 Prompt 时,也更加区块化、组件化(甚至有人为此还开发了框架),这就要求编写 Prompt 的人始终记住要将某一个独立的功能封装在 XML 标签之间,以方便通过外层传入的 Flags 进行动态增减。
注意看 <agent> 里的 Use write_todos to make a plan and break down tasks.——这一句话就让模型的行为模式从「想到哪走到哪」切换到了「先 plan 再 act」。
工具本身的 schema 非常朴素:
{
"name": "write_todos",
"description": "Creates or updates TODOs for complex, multi-step tasks. Use this when a task benefits from being broken into several actionable items that can be tracked or revised over time, for example deep research or coding. Do not use this for very simple tasks that only require one or two steps. Should call this tool after each TODO is done. Mark the first item as 'in_progress' if applicable.",
"strict": true,
"parameters": {
"type": "object",
"required": ["todos"],
"properties": {
"todos": {
"type": "array",
"description": "A list of TODO items representing the steps or sub-tasks needed to complete a complex task.",
"items": {
"type": "object",
"required": ["content"],
"properties": {
"content": {
"type": "string",
"description": "The text description of the TODO item."
},
"status": {
"type": "string",
"description": "The current status of the TODO item, such as pending, in_progress, or completed."
},
"priority": {
"type": "string",
"description": "The priority level of the TODO item, such as low, medium, or high."
}
},
"additionalProperties": false
}
}
},
"additionalProperties": false
}
}
一个 TODOs 看上去是这样的:
{
"todos": [
{
"content": "搜索张雪机车的基本信息,确认品牌背景和产品线",
"status": "completed",
"priority": "high"
},
{
"content": "查找张雪机车走红的时间节点和关键事件",
"status": "completed",
"priority": "high"
},
{
"content": "分析产品特点:性能、设计、价格等",
"status": "in_progress",
"priority": "medium"
},
{
"content": "研究营销策略:社交媒体、网红推广等",
"status": "pending",
"priority": "medium"
},
{
"content": "收集用户评价和市场反馈",
"status": "pending",
"priority": "medium"
},
{
"content": "综合分析火爆原因,形成结论",
"status": "pending",
"priority": "high"
}
]
}
模型的新行为
加上这一件工具,原来的 Loop 立刻变了形状。拿上一章那个问题——「帮我调研一下 2026 年中国新能源车出海欧洲的现状」——接下来的 transcript 大致是这样:
user: 帮我调研 2026 年中国新能源车出海欧洲的现状
assistant → tool_use: write_todos([
{ content: "了解 2026 年中国新能源车出口欧洲的整体规模", status: "in_progress" },
{ content: "梳理主要玩家及其在欧份额", status: "pending" },
{ content: "了解欧盟关税政策与反补贴调查进展", status: "pending" },
{ content: "总结本地化建厂与渠道布局", status: "pending" }
])
assistant → tool_use: web_search("2026 中国新能源车 欧洲 出口 数据")
... (web_search / web_fetch 若干轮) ...
assistant → tool_use: write_todos([
{ content: "了解 2026 年中国新能源车出口欧洲的整体规模", status: "completed" },
{ content: "梳理主要玩家及其在欧份额", status: "in_progress" },
...
])
... (继续执行剩余项) ...
assistant: <final answer>
和纯 ReAct 多轮相比,最大的差别——开头那一下 write_todos,把答题的「考纲」预先写死了。执行时漏掉一个维度,在 plan 上就会留下一个 pending 没划掉,模型自己会回过头来补。
画成图对比一下。先看纯 ReAct 多轮:
每一步只看当下的 tool_result,不回头也不前瞻。再看 Plan-then-Act:
多出来的是开头的 plan 和每一步之后回头更新状态。Loop 没变,只是多了一件工具、多了一条 system prompt 的指令。
你知道吗——为什么 write_todos 是工具,不是 prompt 里的结构化字段?
这个设计挺微妙。最朴素的做法是在 system prompt 里加一段「请先输出一个 <plan>...</plan> 块,再开始行动」——但这种 plan 只是一段文本,模型在后面的回合里可以装作没看见。把 write_todos 做成工具之后,plan 的产出变成了一次真正的 tool_use / tool_result 往返,会被原封不动地保留在 context 里;更关键的是,模型对自己「调用过的工具」有非常强的「已承诺」感——这是 RLHF 训出来的结构性倾向。工具调用在它眼里是动作,prompt 里的文本是建议。这两者的份量不一样。
到这里,Plan-then-Act 的骨架就搭完了。但实战中你很快会撞见两个小坑:
一是不熟悉的话题上,plan 会跑偏——模型对这个领域本来就一知半解,凭着半吊子理解列出的 4 个子任务,可能从一开始就漏了最关键的那一维。
二是跑到一半,模型会忘了更新 todos——明明做完了第二项,却不调 write_todos 把它划成 completed,也不把刚发现的一个新子任务补进去。Plan 就这么一点点失效了。
下面两节,分别打两个小补丁。
补丁 A:Plan 之前先做一次 briefing
Plan-then-Act 的第一个坑很好理解——模型不能 plan 自己不认识的东西。
假设用户抛过来一个冷门术语,比如「帮我调研一下 pp-ocr 在长尾中文古籍场景下的表现」。模型心里对 pp-ocr 只有一个模糊印象(「好像是百度开源的 OCR 引擎?」),直接 write_todos 的话,大概率会列出四条不咸不淡的 plan:查一下是什么、查一下性能、查一下优缺点、总结。真正要紧的维度——它在多语言上的分支、历史版本号、和某个竞品的 benchmark——一个都没踩到。
补丁也很轻。在 system prompt 里明确允许 Agent 在 plan 之前做一次 web_search,只为建立对这个话题的基本认知:
<guidelines>
<guideline for="deep-research">
- Create a research plan using `write_todos`
- Perform a quick `web_search` before planning if you're not familiar with the topic, or the topic may happen after the cut-off date
- Execute the plan step by step or in parallel if applicable
- Dynamically change the TODO plan according to the latest information we collect
</guideline>
</guidelines>
注意这句话里的两个关键词:one-time 和 before planning。它不是给模型一条「搜索随便用」的空白支票,而是一条硬编码到 system prompt 里的协议——在 plan 之前,你可以也只可以用一次 web_search 来给自己做 briefing。
有了这一次 briefing,模型会先搜一把「pp-ocr」、看完前几条结果摘要,知道了它是 PaddlePaddle 体系里的 OCR 模型族,有 v1 到 v5、中英日韩多语种分支、服务器端和轻量端两条路线……带着这份认知再 write_todos,列出的 plan 就会从「查一下是什么」这种无效维度,变成「对比 v4 vs v5 在手写古籍上的识别率」这种有抓手的子任务。
你知道吗——为什么限制「仅一次」? 如果允许 Agent 在 plan 之前无限搜,它会一直搜下去——搜到感觉「差不多了」再开始 plan。那这个 harness 就退化成了纯 ReAct 多轮,plan 这件事形同虚设:所有信息都是在 plan 之前攒齐的,plan 只是把已经知道的东西抄一遍。把额度压到「仅一次」,相当于告诉模型:你对这个话题有一次建立语感的机会,别浪费——用完之后就必须坐下来好好列 plan、再按 plan 去深挖。一次刚好卡在「让 briefing 有意义」和「不抢 plan 主场」的平衡点上。
打完这个补丁,plan 的输入侧就稳了。下一个坑在输出侧——模型跑着跑着容易忘了回头更新 todos。
补丁 B:每一步之后 nudge 一下
第二个坑——模型会忘记维护 todos。
这个现象你肯定见过:开头 plan 列得漂漂亮亮 4 项,第一项做完了,模型就急着开始做第二项;做到第三项的时候,发现需要补一个新的子任务,但它直接就搜了,没把这个新发现追加进 todo list。跑完全程回头看 plan,状态还停在开头那份——第一项之后就再也没更新过。
对这个问题,仅仅在 system prompt 里写一句「记得更新 todos」是不够的。prompt 是一次性铺好的背景板,模型读完前几轮之后,它的注意力权重已经转移到更近处的 tool_result 上了,背景板上的叮嘱会被逐渐淡化。
Harness 的解法叫 nudge(提醒 / 推一把),也叫 system-reminder——在每次最后一次 tool_result 之后、且当前 todo list 非空时,由 harness 硬编码往上下文里追加一条提醒给模型:
<system-reminder>
- There're still some TODOs not marked as 'completed', update the TODO list before your next action
- Running multiple tasks in parallel is allowed, and mark multiple TODOs as 'in_progress' if applicable
- Add/update/remove TODOs from your plan according to the latest information we collect if necessary
<system-reminder>
这条提醒不是用户发来的 message,也不是模型自己生成的 assistant message,而是由 harness 在 tool_result 之后「插播」的一条 system-reminder。从模型视角看,它每做完一件事、正准备盘算下一步时,都会看到这一句在眼前。
画成时序图更清楚:
注意 Harness 的两个动作:一是把 tool_result 原样回传给 LLM;二是在检查到「当前 todo list 非空」时,额外追加一条 system-reminder。两件事在同一个消息里交给 LLM,看起来像是「工具返回自带了一句 nudge」。
关键是——这条 nudge 是每次 tool_result 都打一次的。不是只在开头、也不是隔三差五;只要 plan 还没做完、还在进行中,它就一直打。模型的注意力一直被这条提醒拉回到「我的 plan 进度是怎样的」上面,忘记更新的概率就大大降低。
你知道吗——nudge 与 <system-reminder>?
这种「在特定时机由 harness 主动往 context 里塞一条提醒」的机制,在现代 agent harness 里是常规武器,通称 nudge。Claude Code 里的 <system-reminder> 就是这一套思路——当 harness 检测到某些条件(tool_use 计数达到某个阈值、用户似乎 idle 了一段时间、某个关键文件被修改…),就会往 LLM 的下一次 input 里插入一段系统级的提醒。它既不是 user message 也不是 assistant message,是harness 层打进去的上下文补丁。本文开头你看到的 <system-reminder> 块就是这样来的。nudge 的核心认识是:prompt engineering 是静态的,agent 的行为是动态的——有些问题靠 prompt 写死治不了,只能靠 harness 在运行时针对当前状态主动干预。
补丁 A 治了 plan 的输入侧,补丁 B 治了 plan 的输出侧。加上开头那一件 write_todos 工具,Deep Research 这个场景下的 harness 就算搭完了——从单轮 ReAct,到多轮 Loop,再到 Plan-then-Act 加两个小补丁,一共就这点东西。
但同样一套骨架换一批工具会变成什么?下一章我们把镜头切到写代码的场景。
结构化输出
https://mp.weixin.qq.com/s/smt8VjtHI53-MWGuijagwQ
https://fengchao.pro/blog/llm-structured-output-principles-and-implementation/
LLM 本质上是一个条件概率模型,它根据输入提示词(prompt)预测下一个 token 的概率分布。所谓“结构化输出”,就是让模型在这个概率空间里只采样那些合法的、符合约束的 token 序列。实现方式大致分成两类:软约束(Soft Constraints) 和 硬约束(Hard Constraints)。
软约束通过提示词工程引导模型输出符合规范的文本;而硬约束则通过实时解析和 token-level 检查,直接约束模型的采样过程。
Prompt
自我验证
单纯依赖提示词引导无法满足生产环境对稳定性和可靠性的要求,我们可以通过自动验证与修复的技术来添加“第二道防线”,以提高输出文本的稳定性和可靠性。不管模型生成什么内容,都要在进入下游流程之前先过一遍结构校验。如果发现格式不合法、字段缺失、类型错误等,框架会自动反馈给 LLM,并要求其重新输出。
首先,我们需要声明期望的输出结构。例如,假设我们希望从财报文本中提取三个字段:公司名称、报告期和营收。我们可以使用 Pydantic 来精确定义这些字段的类型及其合法格式与范围:
class FinancialReport(BaseModel):
company_name: str = Field(validators=[ValidLength(min=1, max=100)])
report_period: str = Field(validators=[RegexMatch(pattern=r"\d{4}Q[1-4]")])
revenue: float = Field(validators=[ValidRange(min=0)])
这样就定义了一个合法的数据结构:
-
company_name的字符串长度在 1 到 100 之间; -
report_period是 2024Q3 这种格式,用正则表达式约束; -
revenue是非负值。
模型给出初始回答后,系统会立刻依据预设的结构规范对其进行校验。若输出本身已经符合要求,就可以直接进入下一步;但如果发现格式不合法、字段缺失或类型不匹配,框架不会直接把错误抛给下游,而是主动再次调用模型,并明确告知其问题所在,让模型按照反馈重新生成答案。这个过程可以反复进行多轮,直到得到一个严格满足结构约束、能够被程序稳定解析的结果。
支持结构化输出的开源框架有很多,例如 instructor、marvin、mirascope 等。以 instructor 库为例,它的自动验证与修复机制大致实现在两个核心位置:
-
core/retry.py:负责调用模型 + 解析 + 捕获异常 + 重试的主循环。 -
response.py:负责把这一次解析失败的信息,转化成下一轮请求的补充提示,也就是 reask。
约束解码
前面介绍的提示词引导和验证修复方法,本质上都属于"软约束":提示词引导依赖模型的自主遵守,验证修复则是在输出完成后再进行检查。这两种方法都无法从根本上杜绝格式错误的产生。而约束解码(Constrained Decoding) 则采用了完全不同的思路——它在模型生成的每一步就直接施加约束,从源头上确保输出的合法性。
约束解码的核心原理是对模型的采样过程进行实时干预。LLM 在生成文本时,每一步都会计算词表中所有 token 的概率分布,然后从中采样出下一个 token。约束解码器会在这个采样之前介入:它根据预定义的语法规则(例如 JSON Schema 对应的有限状态机),判断当前状态下哪些 token 是合法的,哪些会导致违反格式约束。所有不合法的 token 会被直接屏蔽,模型只能从剩余的合法 token 中进行选择。
技术上,约束规则可以用多种形式表达:JSON Schema、正则表达式或上下文无关文法(CFG)等。这些规则会被编译成有限状态机(Finite State Machine, FSM),在解码过程中实时追踪当前的语法状态。例如,在生成 JSON 对象时,FSM 会记录当前是在对象开始、键名、值还是结束位置,据此计算下一个允许出现的字符集合。这样就能确保每个括号、引号、逗号都出现在正确的位置,从而保证最终输出是一个完全合法的 JSON 字符串。
相比前两种方法,约束解码的最大优势是接近 100% 的格式准确率。由于每个 token 都经过了合法性检查,格式错误从机制上被完全杜绝了。
然而,约束解码也面临一些实际挑战:
- 对模型内部访问权限的要求
传统的约束解码需要访问模型输出的完整概率分布(logits),以便对 token 进行过滤。但许多闭源的 LLM 不对外提供 logits,这使得约束解码无法直接应用。针对这个问题,研究者提出了"草图引导"(Sketch-Guided Constrained Decoding)等替代方案:先让黑盒模型自由生成一个"草稿",再用本地部署的白盒模型(可以访问 logits)根据约束规则对草稿进行精炼和修正,从而在不访问黑盒模型 logits 的情况下实现类似的效果。
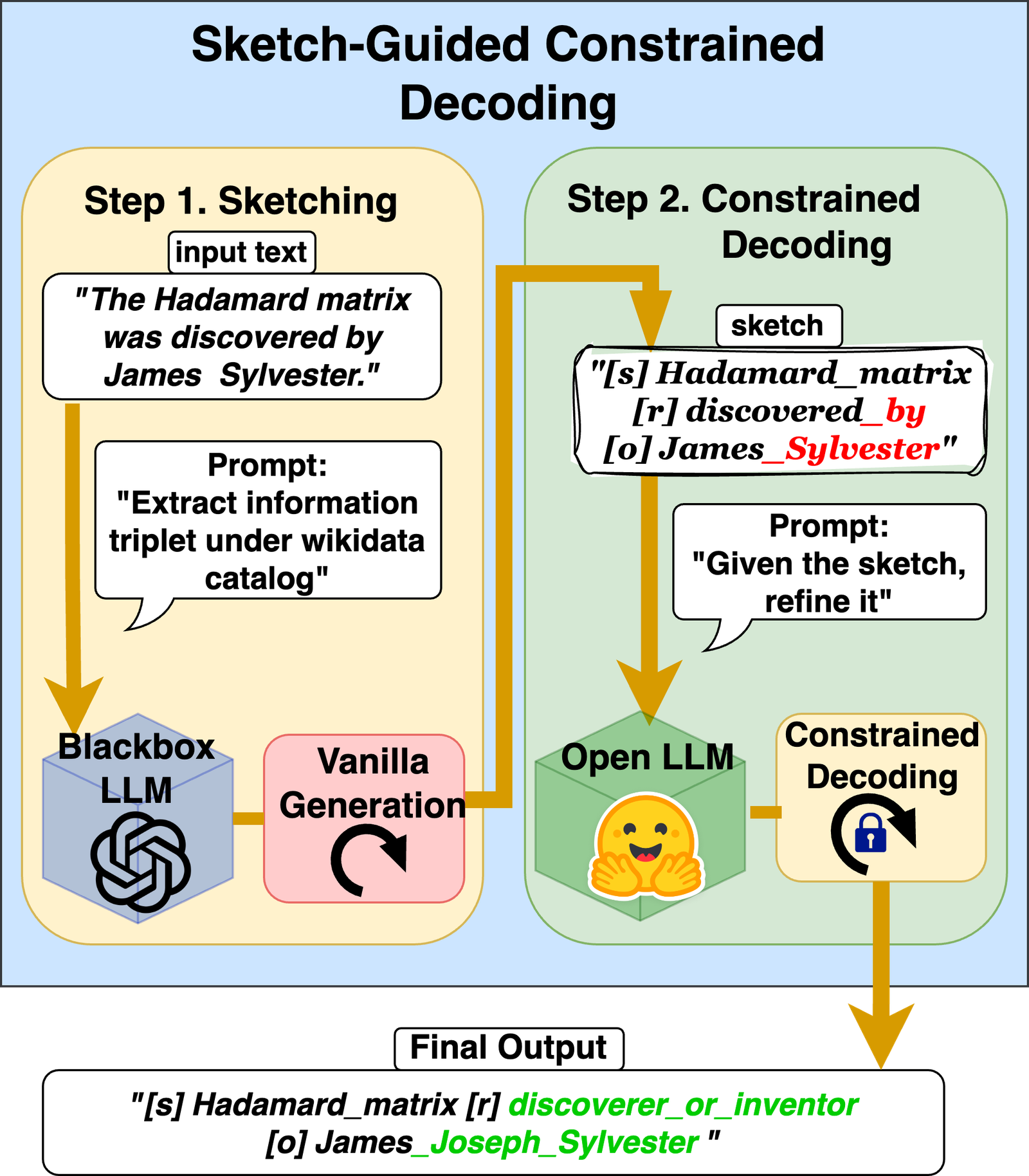
- 格式约束对内容质量的影响
当模型被迫遵守严格的格式约束时,其推理能力可能会受到影响——格式限制越严格,模型在复杂推理任务上的表现下降越明显。这是因为格式约束会限制模型的"思考空间",迫使它在生成内容的同时还要兼顾格式规范,从而分散了计算资源。
一个解决方法是"先思考后格式化"(NL-to-Format):让模型先用自然语言完整地进行推理和回答,不受任何格式约束;待内容生成完毕后,再让模型将自然语言答案转换为目标格式。这种方式将内容生成与格式遵循解耦,既保持了模型的推理质量,又能得到规范的结构化输出。
接口能力
前面讨论的各种技术——无论是约束解码、验证修复还是强化学习——大多需要开发者自己实现或依赖开源框架来完成。现在,主流大语言模型服务商已经将结构化输出作为原生 API 能力内置到产品中。
根据 OpenAI 的文档,开发者只需用 Pydantic 定义好数据模型,API 就会保证返回的数据严格符合定义,开发者可以像调用强类型函数一样直接使用返回值。
from openai import OpenAI
from pydantic import BaseModel
import json
client = OpenAI()
# ===================================================
# === 以前的做法:让模型返回“像 JSON 的文本”,自己解析 ===
# ===================================================
prompt = """
请从下面这句话中提取事件信息,返回 JSON:
- name: 事件名称
- date: 日期(字符串)
- participants: 参与人列表
"""
user_text = "Alice and Bob are going to a science fair on Friday."
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": prompt + "\n\n" + user_text},
],
)
raw_text = completion.choices[0].message.content
try:
data = json.loads(raw_text)
# 手动校验字段
if "name" not in data or "date" not in data or "participants" not in data:
raise ValueError("缺少字段")
if not isinstance(data["name"], str):
raise TypeError("name 必须是字符串")
if not isinstance(data["date"], str):
raise TypeError("date 必须是字符串")
if not isinstance(data["participants"], list):
raise TypeError("participants 必须是列表")
event_old = data
except Exception as e:
print("解析失败:", e)
event_old = None
# ===================================================
# === 现在的做法:使用 Pydantic + responses.parse ===
# ===================================================
class CalendarEvent(BaseModel):
name: str
date: str
participants: list[str]
response = client.responses.parse(
model="gpt-4o-2024-08-06",
input=[
{"role": "system", "content": "Extract the event information."},
{"role": "user", "content": user_text},
],
text_format=CalendarEvent,
)
event_new: CalendarEvent = response.output_parsed
print("旧做法:", event_old)
print("新做法:", event_new)
原生 API 中结构化输出能力的好处是:
-
端到端保障:开发者只需定义数据模型,API 自动确保输出符合规范,无需编写复杂的验证逻辑。
-
类型安全:从 API 返回的数据可以直接使用,就像调用强类型语言的函数一样可靠。
-
降低门槛:底层的约束解码等复杂技术被完全抽象化,开发者无需了解实现细节,也不需要接入复杂的自动验证与修复框架。
结构化输出的数据结构选型
结构化输出。在`LangGraph`中,实现结构化输出可以通过以下三种有效方式完成:
-
提示工程:指示大模型以特定格式做出回应。
-
输出解析器:采用后处理的方法从大模型的响应中提取结构化数据。
-
工具调用:利用一些内置工具调用功能来生成结构化输出。
从结果可以明显看出,通过定制化的输出解析器得到的结果会更加的符合预期,而接下来我们要说的是,在`LangGraph`中我们更常用的,且效果更好的是,直接使用其内置的工具方法:`.``with_structured_output``()`。
这个方法通过接受一个定义了所需输出属性的名称、类型和描述的模式作为输入,进而生成一个类似模型的 Runnable。不同于常规模型输出字符串或消息,这个 Runnable 输出一个与输入模式相匹配的对象。可以通过几种方式指定这种架构,包括 TypedDict 类、JSON Schema 或 Pydantic 类。如果采用 TypedDict 或 JSON Schema,Runnable 将输出一个字典;若使用 Pydantic 类,则输出一个 Pydantic 对象。我们可以依次的来实践一下。
Pydantic 类做结构化输出
from typing import Optional
from pydantic import BaseModel, Field
# 定义 Pydantic 模型
class UserInfo(BaseModel):
*"""Extracted user information, such as name, age, email, and phone number, if relevant."""*
* *name: str = Field(description="The name of the user")
age: Optional[int] = Field(description="The age of the user")
email: str = Field(description="The email address of the user")
phone: Optional[str] = Field(description="The phone number of the user")
structured_llm = llm.with_structured_output(UserInfo)
# 从非结构化文本中提取用户信息
extracted_user_info = structured_llm.invoke("我叫木羽,今年28岁,邮箱地址是snow@gmial.com,电话是1234567052")
print(extracted_user_info)
TypedDict 类做结构化输出
如果不想使用 `Pydantic`去明确地验证输出参数,则可以使用 `TypedDict` 类定义结构化输出的模式。这就可以使用我们上节课详细介绍的特殊`Annotated`语法,添加对指定字段的默认值和描述
from typing import Optional
from typing_extensions import Annotated, TypedDict
# 定义 TypedDict 模型
class UserInfo(TypedDict):
*"""Extracted user information from text"""*
* *name: Annotated[str, ..., "The user's name"]
age: Annotated[Optional[int], None, "The user's age"]
email: Annotated[str, ..., "The user's email address"]
phone: Annotated[Optional[str], None, "The user's phone number"]
structured_llm = llm.with_structured_output(UserInfo)
# 从非结构化文本中提取用户信息
extracted_user_info = structured_llm.invoke("我叫木羽,今年28岁,邮箱地址是snow@gmial.com,电话是1234567052")
print(extracted_user_info)
Json Schema做结构化输出
对于Json Schema格式大家应该最为熟悉,不需要导入或类,可以直接通过字典的形式清楚地准确记录每个参数,但代价是代码会更加冗长。如下所示user_info 的 JSON Schema,用于描述用户信息的结构,包括姓名、年龄、邮箱地址和电话号码。
# 定义 JSON Schema
json_schema = {
"title": "user_info",
"description": "Extracted user information",
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "The user's name",
},
"age": {
"type": "integer",
"description": "The user's age",
"default": None,
},
"email": {
"type": "string",
"description": "The user's email address",
},
"phone": {
"type": "string",
"description": "The user's phone number",
"default": None,
},
},
"required": ["name", "email"],
}
structured_llm = llm.with_structured_output(json_schema)
# 从非结构化文本中提取用户信息
extracted_user_info = structured_llm.invoke("我叫木羽,今年28岁,邮箱地址是snow@gmial.com,电话是1234567052")
print(extracted_user_info)
Context engineering - prompt
Context engineering - Memory
memory的机制(作用)
https://developer.aliyun.com/article/1677492
- 上下文保持(Context Preservation)
存储对话历史、工具调用记录等,确保多轮交互中Agent能理解用户意图的连贯性。例如,用户问“上海天气如何?”后追问“明天呢?”,Agent需记忆前一轮的“上海”地理位置
- 状态持久化(State Persistence)
支持断点续传:通过Checkpoint机制(如MemorySaver或PostgresSaver)将运行时状态序列化存储,崩溃后可从最近状态恢复,避免重复计算。
典型场景:长时间运行的任务(如代码生成)中途中断后,可从上次保存的步骤继续。
- 个性化适配(Personalization)
记忆用户偏好或历史行为(如常查询的城市),实现定制化响应。
- 协作与隔离(Multi-agent Coordination)
通过thread_id隔离不同用户/任务的记忆,避免数据混淆。例如,多用户对话中,每个用户的会话历史独立存储。
- 资源优化(Token Efficiency)
动态修剪或摘要历史消息(如trim_messages),避免上下文窗口溢出或token浪费。例如仅保留最近3条消息或按token数截断。
memory分类
https://mp.weixin.qq.com/s/gep-kwFdFK4QocCCqgyooQ
https://mp.weixin.qq.com/s/1Lr66PClL3CzyJsQ2KFPmQ
长短期记忆
- 短期记忆:
本质:就是上下文窗口内的 对话历史,存储在 KV Cache 或者文本 buffer 里。
使用场景
• 聊天机器人(连续对话)
• 任务执行中,需要记住上一轮用户的指令
- 长期记忆:
本质:把对话内容、用户信息等存入一个外部数据库(向量库/知识库),通过 检索 机制在需要时取出。
使用场景
• 长期陪伴型智能体(记住用户的兴趣、习惯)
• 多会话场景(跨会话记忆,不仅限于一次对话)
• Agent 需要跨天/跨周执行任务(如知识管理、个人助理)
记忆的存储形式
-
令牌级记忆 (Token-level):外部显式存储(如向量库、知识图谱)。它的优势在于透明、易编辑,是法律、金融等高合规行业的首选。
-
参数化记忆 (Parametric):内化在模型权重中。通过微调或 LoRA,Agent 习得行业直觉和企业风格。
-
潜层记忆 (Latent):存在于内部隐藏状态(如 KV Cache)。它响应最快,是实时复杂决策的基石
memory策略
https://mp.weixin.qq.com/s/29SXiWyRgIZNGgpY3E0jdw
顺序记忆/全量记忆--全量保存
概念:将每轮对话按顺序累积在“对话历史”中,每次回复时都将完整历史作为上下文提供给模型
模拟代码;
history = []
def add_message(user_input, ai_response):
turn = {
"user": user_input,
"assistant": ai_response
}
history.append(turn)
def get_context(query):
return concat_all(history)
**优点:**实现简单,无需复杂算法;完整保留了所有细节,信息不丢失。
**缺点: **对话稍长可能会触发上下文长度上限,模型需要处理越来越多的文本,导致响应变慢且成本升高。一旦超过模型上下文窗口,早期内容不得不被截断,重要信息可能丢失。此外,长期保留大量不相关旧信息也可能干扰模型判断。
【适合场景】
仅适用于对话轮次很少或者内容短的场景,比如简单QA或一次性问答。在这些情况下,全量记忆确保即使用户提及之前的话题,智能体也不会遗漏。但很显然在大多数实际应用中,这种策略不可持续。
滑动窗口--保存最近的
针对全量记忆的弊端,最简单的改进是限制记忆长度:人类对话中,我们往往只关注最近的信息,旧话题慢慢就淡忘了。滑动窗口策略正是模仿这种特性:只保留最近的若干轮对话,将更早的内容遗忘,以控制上下文长度。
伪代码:用队列模仿
memory = []
WINDOW_SIZE = 3 # 最多保留 3 轮完整对话
def add_message(user_input, ai_response):
turn = {
"user": user_input,
"assistant": ai_response
}
memory.append(turn)
if len(memory) > WINDOW_SIZE:
memory.pop(0) # 移除最早一轮问答
def get_context(query):
return concat_all(memory) # 返回最近几轮对话
基本原理:针对全量记忆的弊端,最简单的改进是限制记忆长度:人类对话中,我们往往只关注最近的信息,旧话题慢慢就淡忘了。滑动窗口策略正是模仿这种特性:只保留最近的若干轮对话,将更早的内容遗忘,以控制上下文长度。
【特点分析】
**优点: **实现非常简单,开销低,不需要引入外部存储;确保模型上下文始终在设定大小内,响应速度和成本相对可控 。
**缺点:**健忘性强,一旦窗口滑过,旧信息就永久丢失,无法支持真正的长期记忆 。如果用户稍后又提及早前内容,智能体因已遗忘就无法关联。此外窗口大小也难以抉择:太小会过早遗忘历史,太大又降低了节省上下文的意义。
【适用场景】
滑动窗口适用于短对话场景或对历史依赖不强的任务。例如FAQ助手、简单闲聊机器人等,不需要长久记住早先话题 。本质上你需要考虑取舍:通过遗忘来换取性能和成本,但不适合需要长程依赖的对话。
相关性过滤--保留重要的
人类会选择性记忆,对无关紧要的事很快忘掉。类似地,智能体的记忆也可以有所取舍:优先保留重要信息,丢弃无用细节。相关性过滤策略就是基于信息的重要程度来管理记忆,而不是简单的抛弃旧记忆。
【基本原理】
系统为每条记忆分配一个“重要性”或“相关性”评分(Score),根据评分高低决定保留或清除。当新信息进入,导致容量超限时,自动删除评分最低的记忆 。
评分可以依据多种因素:与当前对话主题的相关程度、最近被提及的频率、信息本身的重要度(例如包含用户关键偏好的句子打高分)等。
伪代码:实现时,可用一个列表或优先队列按分值排序。模拟如下:
memory = []
MAX_ITEMS = 25
def add_message(user_input, ai_response):
item = {
"user": user_input,
"assistant": ai_response,
"score": evaluate(user_input, ai_response),
}
memory.append(item)
if len(memory) > MAX_ITEMS:
# 找出得分最低的项
to_remove = min(memory, key=lambda x: x["score"])
memory.remove(to_remove)
def get_context(query):
# 返回按对话顺序排列的高分记忆
return concat_all(sorted(memory, key=lambda x: x["order"]))
优点: 保证关键知识不会遗忘,因为重要内容打分更高。相比盲目的窗口截断,这种策略更“智能”,能腾出空间的同时尽量不丢关键信息。
缺点: 如何准确评估“重要性”是难点,可能需要额外模型计算语义相关度或预定义规则。评分机制不完善时,可能误判重要性,删错记忆。此外,它不像滑动窗口那样可预测,会给调试和理解上带来复杂性。
【适用场景】
适合信息密集且需要筛选的场景,如知识型对话机器人或研究助理工具。在这些应用中,用户提供的大量信息需要智能体加以取舍。例如:一个智能医学助手从患者冗长描述中挑出病史要点存储。
摘要/压缩--提炼关键信息
有没有办法在不丢失重要信息的前提下缩短对话长度?摘要策略由此诞生。其动机是像人类做笔记一样,将冗长的对话内容去除无用的信息(寒暄、闲聊、重复信息等),浓缩成关键要点(事实、关键数据、兴趣爱好等)保存 。这样既保留了核心信息,又能大量节省上下文窗口空间,缓解记忆无限增长的问题。
在实际实现中,可以结合滑动窗口策略:超出窗口的对话才进行摘要与压缩。
摘要可以由一个LLM生成
【基本原理】
在对话过程中定期将较早的对话内容生成摘要与压缩,并用这个摘要代替原始详细内容存入记忆。摘要可以由一个LLM生成。例如,每当对话超过预定长度(窗口大小)时,把最早的几轮对话拿出来总结,模拟如下:
memory = []
summary = None
MAX_LEN = 10 # 最多保留 10 轮问答
def add_message(user_input, ai_response):
turn = {
"user": user_input,
"assistant": ai_response
}
memory.append(turn)
if len(memory) > MAX_LEN:
old_turns = memory[:-5]
summary_text = summarize(old_turns)
summary = merge(summary, summary_text)
memory.clear()
memory.append({"summary": summary})
memory.extend(memory[-5:])
def get_context(query):
return concat_all(memory) # 返回摘要 + 最近对话轮
优点: 大幅节省上下文长度,长期记忆能力强——理论上,通过不断摘要,早期信息的要点可一直保留 。同时,摘要内容精炼,有助于模型聚焦关键信息。
缺点: 摘要质量取决于LLM,也可能遗漏细节或引入信息偏差。如果摘要不准确,后续智能体基于摘要的生成可能出错。此外生成摘要本身需要耗费额外计算,对实时对话有延迟影响。
【适用场景】
摘要记忆适用于长对话且需要保留上下文要点的场景:智能体需记住用户的关键信息(姓名、喜好、诉求等)但不必逐字记住用户每句话。比如一个AI心理陪伴助手。AI可以采用摘要策略,每次对话结束后将本次谈话要点总结存储。下次可以通过之前的摘要回顾用户曾提到的主要问题和情绪变化,从而提供连续性的回应。
向量数据库--语义检索记忆
对于海量长期记忆,一个理想方案是将知识存入一个外部数据库,在需要时再调取。这类似人类查笔记或资料库。向量数据库记忆策略利用向量化嵌入(Embedding),将对话内容在向量库存储,并在需要时通过语义检索相关记忆 。其动机在于突破LLM上下文窗口限制,实现近乎无限的外部长时间记忆。
【基本原理】
将每次对话嵌入后存入向量数据库如 Chroma、Pinecone 等 。当需要记忆时,把当前对话内容也向量化,并在数据库中搜索语义相近的记忆片段,将最相关的若干条取出,添加到模型的上下文。模拟如下:
# 初始化向量存储
memory = VectorStore()
def add_message(user_input, ai_response):
turn = {
"user": user_input,
"assistant": ai_response
}
embedding = embed(turn)
memory.add(embedding, turn)
def get_context(query):
q_embedding = embed(query)
results = memory.search(q_embedding, top_k=3)
return concat_all(results) # 返回语义最相关的对话轮
优点:语义级别的智能检索,能根据内容语义而非关键词匹配相关记忆 。存储容量大,向量数据库可无限扩展,以支持真正的长期记忆,且检索效率高。
缺点: 依赖嵌入模型质量,若向量表示不好,检索结果也可能风马牛不相及 。向量存储与搜索有一定的计算代价,当记忆库很大时,每次相似度计算也会消耗算力 。另外需要部署维护额外的数据库服务,增加系统复杂度。
【适用场景】
需要长期记忆的对话系统,如个性化助理等。这类系统往往需要记住用户跨会话提供的信息,也非常适合在聊天之外存储知识或用户背景(因为有向量库),让记忆检索具备类似RAG的效果。比如: 一个法律咨询AI,当用户提问复杂法律问题时,AI可以同时检索出相关的记忆和法律知识,用来做增强生成。
知识图谱:结构化记忆
**纯粹依赖向量相似度的记忆系统往往将知识视作离散内容,缺乏对知识之间关系的理解 **。知识图谱记忆策略旨在以结构化方式存储和组织记忆信息,通过显式的实体、属性和关系来增强智能体的长期结构化记忆和推理能力 。
【基本原理】
智能体将对话和交互中提及的实体、属性和关系这样的事实信息提取出来,逐步构建起一个知识图谱。比如对话中有“小刘加入了阿里巴巴公司”,那么提取三元组:(小刘, 就职于, 阿里巴公司)。除此之外,还可以记录事件发生的时间等(形成时序知识图谱以处理随时间变化的知识 )。
当需要记忆检索时,智能体可以查询知识图谱:比如先找到相关联的节点、沿关系链追溯信息,甚至进行路径上的逻辑推理,最后将查询或推理出的信息加入上下文。
graph = KnowledgeGraph() # 初始化知识图谱对象
def add_message(user_input, ai_response):
# 将一轮对话转化为结构化三元组 (实体1, 关系, 实体2)
full_text = f"User: {user_input}\nAI: {ai_response}"
triples = extract_triples(full_text) # LLM提取三元组
for s, r, o in triples:
graph.add_edge(s.strip(), o.strip(), relation=r.strip())
def get_context(query):
# 提取查询中可能涉及的实体
entities = extract_entities(query)
context = []
for e in entities:
context += graph.query(e) # 查询图谱中与实体相关的信息
return context
优点: 将记忆结构化后,智能体能进行更精细的检索和推理 。结构化记忆使AI不再只按相似度找段落,而是可基于图谱回答复杂问题(如基于多跳关系推理)。知识图谱还具有可解释性,查询路径清晰可追溯,这在需要准确溯源的应用中很有价值。
缺点: 构建和维护成本高:需要借助LLM抽取知识,可能出错或不完整;图谱规模大时也会面临查询性能和存储问题。同时,知识图谱擅长明确事实推理,但对于模糊语义的匹配可能还需要配合向量搜索。
【适用场景】
适合知识密集型应用和需要跨事件推理的智能体。例如企业客户支持AI需要理解用户历史提问与账户、订单等信息的关联,或科研助理AI需要梳理论文中的概念关系等。
分层记忆:短期与长期结合
人类记忆是有层级分工的:有的内容转瞬即忘(如刚听到的一句话),有的会短时间记住(如今天开会要点),而真正重要的内容(如家庭住址、生日)会长期保留。
分层记忆策略旨在构建类似“人脑”的记忆结构:将不同类型、重要程度的信息存入不同层级的存储系统,让智能体在面对不同场景时都能“对症下药”。
【基本原理】
该策略将记忆系统划分为多个层级:
-
工作记忆(短期):保存最近几轮对话,更新频繁、容量小,通过滑动窗口维护。
-
长期记忆(可检索):将重要信息嵌入后保存,支持跨会话、长期检索。
-
提升机制:比如,当用户在对话中说出类似“记住我XXX”、“我总是”、“我过敏”等关键信息时(也可借助LLM),系统会将这轮信息提升进长期记忆,以供未来使用。
检索时,系统会从短期记忆获取当前上下文,再从长期记忆中基于语义相关性搜索历史记忆,组合出丰富的提示内容交给LLM处理。
这种策略本质上是滑动窗口+向量库+ 重要性判断的组合策略
short_term = SlidingWindow(max_turns=2) # 最近几轮对话
long_term = VectorDatabase(k=2) # 可检索的长期嵌入记忆
promotion_keywords = ["记住", "总是", "从不", "我过敏", "我的ID是", "我喜欢", "我讨厌"]
def add_message(user_input, ai_response):
short_term.add(user_input, ai_response)
# 如果用户的输入中包含提示记忆的关键词,则提升至长期记忆;实际中策略可以更复杂
if any(keyword in user_input for keyword in promotion_keywords):
summary = summarize(user_input + ai_response)
vector = embed(summary)
long_term.add(vector, summary)
def get_context(query):
# 获取短期上下文
recent = short_term.get_context()
# 向长期记忆查询相关内容
vector_query = embed(query)
related = long_term.search(vector_query)
# 拼接上下文作为提示输入
return f"【长期记忆】\n" + concat(related) + "\n\n【当前上下文】\n" + concat(recent)
优点:可以结合短期记忆与长期记忆优势,近期信息及时响应,历史信息可按需检索;而且即使短期记忆滚动遗忘,但长期的重要记忆依然可查。
缺点:这种策略实现上更复杂,需要涉及多个模块(窗口管理、嵌入、召回等);且调优成本更高,比如关键词或重要性的判断、嵌入质量、检索精准性、组合上下文策略均需调试。
【适用场景】
适合需要长期上下文感知的智能体系统。比如企业客服Agent,用户先前的订单、偏好需要记住;再或者个人助理类AI,跨天甚至跨月记住日程安排、家庭成员信息;或者教学/医疗场景中需要回顾过往重要的问答、诊断建议、学习习惯等。
分层记忆:四层记忆金字塔
L0: 缓冲记忆 (Buffer Memory / Short-term)
-
**定义:**此时此刻的对话上下文(Working Context)。
-
**形态:**内存或 Redis 中的 List[Message]。
-
**核心痛点:**Context Window 昂贵且有限,不能无限追加。
-
工程策略:
- **Sliding Window (滑动窗口):**始终保留 System Prompt(人设)和最近 N 轮对话(例如最近10条)。
- **Token Trimming (智能修剪):**不按条数,而是严格按照 Token 计数进行截断。LangChain 的 Trim Messages 中间件可以在调用 LLM 前动态计算并修剪历史,防止 API 报错。
-
**作用:**保证模型能“接得住话”,维持对话的瞬时连贯性。
L1: 摘要记忆 (Narrative Memory / Mid-term)
-
定义:对 L0 溢出内容的“有损压缩”。它不是原始对话,而是对过去一段时间经历的叙事性总结。
-
**形态:**存储在关系型数据库或 Markdown 文件中的文本段落。
-
工程策略:Recursive Summarization (递归摘要)。
- 当 L0 缓冲区满时,不直接丢弃旧消息。
- 触发一个轻量级模型(如
gpt-4o-mini),将最早的那几轮对话压缩成一段几百字的“剧情梗概”。 - 将这段 Summary 重新注入到 System Prompt 的
Previous Context字段中。
-
**作用:**让 Agent 记得“昨天我们聊了什么主题”,虽然忘了具体原话,但叙事流(Narrative Flow)没有断。
L2: 语义画像 (Semantic Memory / Long-term Structured)
-
定义:关于用户或世界的事实性知识 (Facts)。它是结构化的、精确的、可查询的。
-
**形态:**JSON Document (MongoDB) 或 Knowledge Graph (Neo4j)。
-
**核心痛点:**如何避免幻觉,精准记住用户的设定?
-
工程策略:Entity Extraction (实体抽取)。
- 在后台运行一个 Analyzer Agent(旁路监听)。
- **Schema Enforce (模式约束):**为了防止字段混乱,通常需要预定义 Schema(如 career, family, preferences),确保提取的数据结构统一。
- 执行** Upsert (更新或插入)操作:**如果用户说“我换工作了”,系统应更新 Profile 中的 Current_Job 字段,而不是追加冲突信息。
-
**作用:**记住用户的“设定”和“偏好”,实现个性化服务。
L3: 情景记忆 (Episodic Memory / Long-term Unstructured)
-
定义:过去的经历、经验和具体案例。它是非结构化的,基于相似性触发。
-
**形态:**Vector Embeddings (存放在 Pinecone/Milvus/Weaviate)。
-
**核心痛点:**如何让 Agent 举一反三,利用过去的经验解决新问题?
-
工程策略:Dynamic Few-shot (动态少样本)。
- 将过去成功的任务案例、类似的情感交流片段向量化存储。
- 当遇到新问题时,先在向量库中检索最相似的 Top-3 “过去经验”。
- 将这 3 个经验作为 Few-shot Examples 动态插入 Prompt。
-
**作用:**让 Agent 具备“经验感”,越用越聪明。
类OS内存管理:模拟Swap原理
在计算机中,操作系统通过“主内存 + 硬盘”的组合机制高效地管理有限的物理内存(RAM)与大容量但较慢的磁盘(Disk)。如果借鉴这种机制,也可以为智能体构建一种类OS内存管理的记忆系统:将有限的上下文窗口当作RAM使用,而将超出上下文的信息保存到外部存储中(Page Out),必要时再“交换”回来(Page In)。
这种模式与分层记忆模式有点类似,但区别在于:
分层记忆只将关键信息进入二级记忆;而这里只要是窗口外的就会Page Out
分层记忆从二级存储直接检索相关记忆,而这里需要Page In后变成活动记忆
【基本原理】
该策略分为两个层级:
-
活动记忆:使用一个滑动窗口,保存最近的对话。访问速度快,但容量有限。
-
被动记忆:当活动记忆满了,最旧的内容会被“交换”至外部存储。这些信息虽然不直接在模型当前上下文中,但仍可随时检索。
这种策略有一个“页故障”的机制:当用户提问中包含关键词,而这些关键词所需的信息不在当前RAM中,系统就会触发“Page Fault”,从被动记忆中搜索匹配内容,并“page in”上下文,再供LLM使用。
该策略本质上模拟了OS的虚拟内存管理原理,即“冷热数据分层”的上下文利用。模拟如下
active_memory = Deque(maxlen=2) # 快速但小的上下文窗口
passive_memory = {} # 持久存储的被动记忆
turn_id = 0 # 每轮对话唯一标识
def add_message(user_input, ai_response):
global turn_id
turn = f"User: {user_input}\nAI: {ai_response}"
if len(active_memory) >= 2:
old_id, old_turn = active_memory.popleft()
passive_memory[old_id] = old_turn # pageout到被动存储
active_memory.append((turn_id, turn))
turn_id += 1
def get_context(query):
context = "\n".join([x[1] for x in active_memory]) # 当前活动记忆上下文
paged_in = ""
#这里共关键词模拟判断需要pagein的记忆,实际应用策略更复杂
for id, turn in passive_memory.items():
if any(word in turn.lower() for word in query.lower().split() if len(word) > 3):
#需执行page in的动作,略
paged_in += f"\n(Paged in from Turn {id}): {turn}"
return f"### Active Memory (RAM):\n{context}\n\n### Paged-In from Disk:\n{paged_in}"
**优点:**该策略最大优势在于结构清晰且符合计算机原理。它通过将对话拆分成“热数据(当前上下文)”和“冷数据(外部存储)”两层管理,有效缓解上下文窗口限制,同时还能在关键时刻回忆过去的重要信息,大大提高记忆系统的灵活性和扩展性。
**缺点:**实现上需要模拟“page in/out”逻辑,并确保触发时机(比如根据关键词或向量相似)的准确性。如果触发机制设计不佳,可能会出现信息召回不及时或漏召的情况,从而影响对话连贯性。同时,“分页”机制要求设计良好的上下文拼接逻辑。
【适用场景】
适用于上下文窗口受限但又需要长期记忆的智能体系统。它能够在保持对话响应速度的同时,保留大量历史信息,适合低延迟对话、时间跨度较大的任务型助手,以及需要随时回溯旧信息的场景:当用户提出涉及过往内容的问题时,系统可以像操作系统一样将“被交换出去”的记忆及时“唤醒”,实现高效又节省资源的记忆管理。
最佳实践
https://mp.weixin.qq.com/s/sARM1GWhKQAHEInhEheZiA
https://mp.weixin.qq.com/s/AeqetxatPrZXapanYWRC6g
不要相信所谓“无限上下文”能解决一切。生产环境建议采用 Redis (实时工作记忆) + Postgres (结构化业务事实) + 向量/图数据库 (长期经验知识) 的三层架构。
chatgpt的memory机制
ChatGPT 的 Memory 功能不仅仅是一个“存储桶”,而是一个精密的双通道动态系统。
-
写入机制:显式与隐式的双重奏
- **显式指令 (Explicit Instruction):**当用户说“记住我女儿叫 Alice”时,主模型会调用一个类似于 save_memory 的内部工具,将该事实直接写入用户的长期记忆库。
- **隐式习得 (Implicit Learning):**这是一个更高级的后台进程。如果在多轮对话中,用户反复表现出对“Python 代码”的偏好,或者总是要求“用简洁的语气回答”,后台的分析 Agent(Profiler)会捕捉到这一模式,并将其抽象为一条偏好规则存入记忆。
-
读取机制:动态系统提示词 (Dynamic System Prompt)
- ChatGPT 不会将所有记忆一次性塞入 Context。它会在每轮对话开始前,进行一次预检索 (Pre-retrieval)。
- **流程:**用户提问 -> 检索相关记忆 -> 动态生成 System Prompt -> 调用模型。
- **效果:**System Prompt 会从标准的“你是一个助手”动态变为 -> “你是一个助手。用户偏好 Python。用户女儿叫 Alice。”
-
核心护栏:隐私即产品 (Privacy as Product)
- Memory 最大的工程挑战不是技术,而是信任。ChatGPT 设计了一个可视化的 “Manage Memory” 面板。
- 用户可以逐条查看系统记住了什么,并拥有**“一键遗忘”**的权利。这种将“黑盒记忆”白盒化的设计,是 AI 产品商业化落地的关键护栏。
cursor的memory机制
作为 AI 编程助手,Cursor 记住的不是代码的“文本片段”,而是代码的逻辑结构。这是通用 RAG 在垂直领域失效的原因——代码需要的是精确的依赖关系,而不是模糊的语义相似度。
-
影子工作区 (Shadow Workspace)与全库索引
- 当你打开项目时,Cursor 会在后台静默构建一个代码库索引 (Codebase Index)。这个索引不是简单的文本切片,而是基于 AST (抽象语法树) 的结构化数据。
- 它清楚地知道
User类定义在models.py,而被views.py引用。这种“记忆”是图状的(Graph-like),而非线性的。
-
多跳检索 (Multi-hop Retrieval) 代替简单相似度
- **场景:**用户问“修改 calculate_tax 函数会有什么影响?”
- **通用 RAG:**搜索包含 calculate_tax 关键词的文件 -> 可能漏掉间接调用的文件。
-
Cursor 的记忆机制:
- **定位:**找到 calculate_tax 的定义。
- **多跳:**在引用图谱上游走,找到所有调用该函数的地方(Call Hierarchy)。
- **上下文注入:**将受影响的代码片段(不仅仅是定义本身)精准注入到 Context 中。
这种机制让 Agent 仿佛拥有了“透视”整个项目的记忆能力,而非仅仅是“搜索”能力。
一个情感陪伴ai
为了将上述理论落地,我们设计一个具体的场景:一个需要陪伴用户数年、记得用户童年创伤、并随着时间推移越来越懂用户的“AI 心理咨询师”。
在这个系统中,我们将采用**“读写分离” (Read-Write Split)** 的架构设计,以确保用户体验的流畅性。
1 架构设计:快读慢写
-
**快读 (Hot Path):**在生成回复前,系统必须在毫秒级时间内完成对 L1、L2、L3 的并行检索,迅速组装 Prompt。
-
慢写 (Background Path):所有的记忆更新(摘要生成、画像提取、向量入库)都在异步队列中完成,绝不阻塞用户当前的对话。
2 记忆管理流水线 (Memory Pipeline) —— 一个完整 Query 的生命周期
假设用户在深夜发送了一条消息:
User: “最近工作压力太大了,晚上总是做那个关于掉牙的噩梦。”
让我们看看系统内部发生了什么:
Step 1: 检索与上下文构建 (Retrieval & Context Construction) —— [Hot Path]
系统接收到消息后,并行发起三个检索请求:
- **查询 L2 (语义画像):**从 JSON Store 中读取用户的 Basic Profile。
- Result:{"age": 28, "job": "Programmer", "history": ["Anxiety"], "family": "Close to mother"}
- **查询 L1 (叙事记忆):**从数据库读取最近几次咨询的 Summary。
- Result: “用户上周刚结束一个高强度的上线项目,情绪处于耗竭状态。”
- **查询 L3 (情景记忆):**将“掉牙的噩梦”转化为向量,在 Vector DB 中检索 Top-1 相似经历。
- Result:检索到 3 个月前的一条记录,当时用户也提到“掉牙”,且那次是因为“担心母亲的健康”。
Step 2: 推理与生成 (Reasoning & Generation) —— [Hot Path]
LLM 接收到的 System Prompt 包含了以上所有信息。它不再是一个瞎猜的聊天机器人,而是一个拥有上下文的专家。
-
LLM 的内心独白:“用户又做这个梦了。上次是因为家庭,这次是因为工作。我要指出这种关联,并给予共情。”
-
Generated Response:“我听到你又做那个关于掉牙的梦了。我记得三个月前你也做过类似的梦,当时是因为担心母亲的身体。这次看来是因为工作的重压引发了类似的焦虑反应。那个项目虽然结束了,但你的紧绷感似乎还没放下,是吗?”
Step 3: 记忆固化与更新 (Consolidation & Update) —— [Background Path]
回复发送给用户后,后台的 Memory Worker 开始工作:
-
**更新 L0:**将最新的问答对追加到 Redis 的滑动窗口中。
-
**触发反思 (Reflection):**Analyzer Agent 分析这段对话:
- Action A:发现用户确认了“工作压力”是新的诱因。更新 L2 画像,在 stressors 列表中添加 "Work/Deadline"。
- Action B:评估这段对话的情绪价值极高(揭示了梦境的模式)。将这段对话进行 Embedding,存入 L3 向量库,并打上标签 tag: dream_pattern ,以便未来再次检索。
- Action C:如果这是今天的最后一段对话,触发 Summarizer 生成今日咨询小结,存入 L1 数据库。
相关开源项目
https://mp.weixin.qq.com/s/ie17hMhEXnZ0OTL5_7ZFag、
https://mp.weixin.qq.com/s/N3IPZYBiYtQLd6KenZPthg
mem0
https://github.com/mem0ai/mem0
memgpt
https://github.com/letta-ai/letta
落盘Offloading:当 Context 装不下
详见[Harness 101: Context Offloading 机制]一文
上一章埋了一根引线——Coding Agent 的 bash、web_fetch、read_file 每一个都可能吐出几千 Token 的结果。一次 grep -rn 扫一个中型仓库,几千行日志;一次 web_fetch 抓一张 API 文档页面,几千 Token 的 HTML 正文。ReAct Loop 转着转着,几十轮下来,messages 历史里堆的几乎全是这些"吃一次就没用了"的 tool_result。
Context Window 不是无限的。200k Token 的模型,看起来很富裕,但跑一个稍长的 Coding Agent 任务,几十轮之后肉眼可见地逼近上限。到时候会发生什么?模型开始漏看前文、开始前后矛盾、甚至直接报错。
Harness 层给这个问题的第一张答卷,叫 Context Offloading。
你知道吗——什么是 Context Offloading? Harness 层的一种机制:当某次 tool call 的参数或返回值体积超过阈值时,Harness 把原始数据写入本地磁盘,在 message 历史里只留一个路径占位符,换取 Context Window 的可回收性。它不是压缩、不是摘要,而是一次"搬家"——数据还在,只是不再常驻上下文。
一句话机制
Offloading 做的事非常朴素:tool_result 太大时,把原始内容写到本地磁盘,Context 里只留一个路径引用。Agent 下次需要时,再用 read_file 把它拉回来。
具体长什么样?一次 bash 调用吐出了 1k Token,Agent 看到的 tool_result 大致是这样:
{
"role": "tool",
"tool_call_id": "call_042",
"content": "[OFFLOADED] saved to abc123.log (1024 tokens). Use read_file to retrieve."
}
原始那 1k Token 没有进入 Agent 的 Context——它被 Harness 截在了返回的路上,搬到了磁盘。Context 里出现的是一个三十几 Token 的占位符。
从 Agent 自己的视角看,这件事甚至是无感的。它照常调用 bash、照常收 tool_result、照常决定"要不要 read_file 拉详细内容"。Offloading 是 Harness 偷偷做掉的事——它不引入新工具,也不改变 ReAct Loop 的任何一环,只是改写了 tool_result 的 payload。
上下文压缩
状态回转Rollback
目前工业界最成熟的解决方案是基于 LangGraph 的 Checkpointer(检查点)机制
通信协议 && Tools
Function call
底层原理和实现
-
结构化定义 (Registration) 在调用开始前,开发者需要用 JSON Schema 定义函数的“说明书”。 名称:函数叫什么。 描述:函数是干什么的(这是模型理解何时调用该函数的关键)。 参数:需要哪些输入,类型是什么(string, int, enum 等)。 这些定义会作为上下文的一部分,通过系统提示词(System Prompt)注入给模型。
-
意图识别与参数提取 (Reasoning & Extraction) 当用户输入指令时,模型并不会直接执行函数,而是进行语义匹配。 判断需求:模型分析用户意图,判断是否需要外部工具。例如,用户问“今天天气如何?”,模型发现自身权重数据不包含实时天气,但配置中有一个 get_weather 函数。 生成指令:模型停止正常的文本生成,转而输出一段符合 JSON 格式的字符串。 常规输出:“今天的天气是...” Function Call 输出:{"name": "get_weather", "arguments": "{"location": "Beijing"}"}
-
外部执行 (Execution) 这一步发生在 LLM 之外(通常是在你的后端代码中)。 解析:你的程序接收到模型生成的 JSON 字符串。 执行:程序根据 JSON 里的名称和参数,真实地去调用 API、查询数据库或运行计算逻辑。 获取结果:得到函数的返回值(如 {"temperature": "25°C", "condition": "Sunny"})。
-
结果回传与二次生成 (Integration) 这是完成闭环的关键一步。开发者将 原始对话记录 + 函数调用请求 + 函数执行结果 全部打包,再次发送给模型。 模型看到执行结果后,会结合上下文,将枯燥的数据转化为自然语言: “北京今天天气晴朗,气温大约 25°C,非常适合出门。”
mcp
官方文档:
https://guangzhengli.com/blog/zh/model-context-protocol/
MCP原理
https://zhuanlan.zhihu.com/p/27327515233
-
MCP 是一个标准协议,如同电子设备的 Type C 协议(可以充电也可以传输数据),使 AI 模型能够与不同的 API 和数据源无缝交互。
-
MCP 旨在替换碎片化的 Agent 代码集成,从而使 AI 系统更可靠,更有效。通过建立通用标准,服务商可以基于协议来推出它们自己服务的 AI 能力,从而支持开发者更快的构建更强大的 AI 应用。开发者也不需要重复造轮子,通过开源项目可以建立强大的 AI Agent 生态。
-
MCP 可以在不同的应用/服务之间保持上下文,从而增强整体自主执行任务的能力。
-
可以理解为 MCP 是将不同任务进行分层处理,每一层都提供特定的能力、描述和限制。而 MCP Client 端根据不同的任务判断,选择是否需要调用某个能力,然后通过每层的输入和输出,构建一个可以处理复杂、多步对话和统一上下文的 Agent。
MCP Servers
https://github.com/punkpeye/awesome-mcp-servers
Crusor+MCP
https://mp.weixin.qq.com/s/j9iz_YRoC40WpiwuIojc8Q
python创建MCP
https://github.com/modelcontextprotocol/python-sdk
Spring ai创建mcp
skills
底层机制
https://github.com/anthropics/skills


如何创建和使用skills
A2A
ANP
CLI
多模态agent
visual prompting
沙盒环境 (Sandbox)
-
核心技术:为 AI Agent 提供的安全、轻量级的微型虚拟机(MicroVM)沙盒环境。它支持在几百毫秒内冷启动一个隔离环境,Agent 可以在里面安全地运行 Python、Node.js,读写文件,甚至启动本地服务器。
-
学习重点:掌握如何通过 API 给大模型分配一个完全隔离的计算环境,以及如何在沙盒与主程序之间进行安全的状态同步。
All-Hands-AI/OpenHands (原 OpenDevin)
-
核心技术:这是一个完整的软件工程 Agent 项目,但它极其依赖底层的沙盒技术(Docker 容器化隔离)。
-
学习重点:不要只看它的皮毛,去深入看它的源码中是如何实现
Action(沙盒内执行命令)和Observation(获取沙盒终端输出)的交互循环的。
可观测性 (Observability)
Agent 的执行路径是非线性的(它可能会循环重试、调用工具、中途报错再修复)。一旦出错,只看传统的 print 日志根本无法排查。
-
- 核心技术:开源的 LLM 工程平台。提供深度的 Trace(追踪)能力,能够将一个复杂任务拆解成树状图,清晰展示每一个环节的 Prompt 输入、输出、耗时(Latency)和 Token 成本(Cost)。
- 学习重点:掌握如何在你自己的代码里打点(Instrumentation),监控多 Agent 协作时的耗时瓶颈。
-
- 核心技术:专门为 Agentic 流程设计的监控工具,支持 Session Replay(会话回放)。
- 学习重点:学习如何追踪 Agent 的“思维链(CoT)”以及它调用外部工具时的失败率。
agent测试
-
核心技术:目前最好用的 LLM 回测 CLI 工具。你可以编写测试用例,用矩阵对比不同的 Prompt、不同的模型在数百个测试用例下的表现,并生成可视化报告。
-
学习重点:将大模型评测整合进 CI/CD 流程(持续集成)。这是高级工程岗位的核心加分项。
-
核心技术:像写 Python
pytest一样写大模型测试。它内置了多种指标(如答案相关性、幻觉率、有害性),并支持 "LLM-as-a-judge"(用强模型当裁判)模式。 -
学习重点:学习如何量化“主观生成内容”的质量,摆脱“肉眼看效果”的初级阶段。
Agent能力评估

GAIA
《GAIA: A Benchmark for General AI Assistants》是一个面向通用AI助手能力的基准评测体系。
1.组成:里面有466个精心设计的问题,其中分为三个级别,Lv.1、Lv.2、Lv.3。
(a) Level 1 :通常不需要工具,或者最多只需要一个工具,但不超过5个步骤。
(b) Level 2:通常涉及更多步骤,大约在5到10之间,需要结合不同的工具。
(c) Level 3 :是一个近乎完美的总助理的问题,要求采取任意长的行动序列,使用任意数量的工具,并进入整个世界。
-
和传统榜单区别:传统的测试一般都是数学(AIME)或者一些专业知识问答、编程等等,但是GAIA测试,里面很多都是概念简单,但是需要多步骤解决的实际问题。
-
如何评估:使用GAIA,只需向人工智能助理给出zero-shot promp。
AgentBench
AgentBench是第一个旨在评估LLM-as-Agent在各种不同环境中的表现的基准测试。它涵盖8个不同的环境(其中5个是首创,另外3个是根据已发布的数据集进行重新编译得到),以更全面地评估LLM在各种场景中作为自主代理运行的能力。
AgentBench相当于是一个通用的LLM评估框架,来评估LLM作为通用Agent在理解人类意图并执行指令、编码能力、知识获取和推理、策略决策、多轮一致性、逻辑推理、自主探索以及可解释的推理这8个方面上的能力。
LangChain评估
工具调用评估为主,LangChain也集成了几个基准(单工具调用、多工具调用、关系数据查询和多元数学问题)来测试LLM在规划、任务分解、函数调用和克服预训练偏差等方面的能力。
-
正确性(与GT相比)-这使用LLM作为判断标准。由于所有这些问题的答案都很简洁,而且相当二元,我们发现这些判断与我们自己的决定相对应。
-
正确的最终状态(环境)-对于打字机任务,每次工具调用都会更新世界状态。
-
中间步骤正确性-每个数据点都有一个最佳的函数调用序列来获得正确的答案。
-
所采取的步骤与预期步骤的比率——尽管选择了一组次优的工具,但代理最终可能会返回正确的答案。
一些学习材料
[4. 理论篇: AI Agents理论知识]
白皮书:https://arthurchiao.art/blog/ai-agent-white-paper-zh
https://www.anthropic.com/engineering/building-effective-agents
教程:https://github.com/datawhalechina/hello-agents
agent开发实战: https://github.com/AIGeniusInstitute/AI-Agent-In-Action?tab=readme-ov-file