
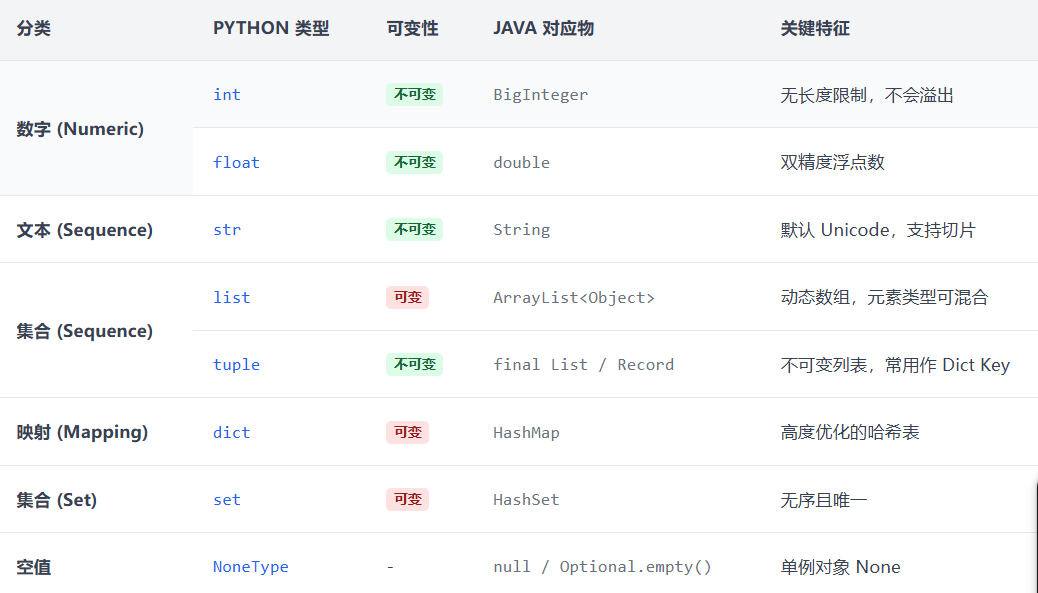
python底层机制
字典驱动
在 Python 中,几乎所有的对象(类、实例、模块、函数)在底层都是一个包裹着 dict(哈希表)的容器。
对象、实例的本质:dict 属性
在 Java 中,如果你定义一个类 User 有 name 字段,这个字段在内存中的偏移量是固定的。但在 Python 中,一个实例的属性是存储在一个名为 dict 的字典里的。
class User:def __init__(self, name):
self.name = name
u = User("Alice")
print(u.__dict__) # 输出: {'name': 'Alice'}# 你甚至可以动态地往字典里塞东西
u.age = 25
print(u.__dict__) # 输出: {'name': 'Alice', 'age': 25}
底层逻辑:当你调用 u.name 时,Python 实际上是在执行 u.dict['name']。
- Java 视角:这相当于每一个 Java 对象内部都自动维护了一个
HashMap<String, Object>来存成员变量。
命名空间的本质:层级化的字典
Python 寻找变量的过程,本质上是在一组字典中进行哈希查找。这被称为 LEGB 规则。
-
L (Local): 函数内部的局部变量字典。
-
E (Enclosing): 闭包环境的字典。
-
G (Global): 当前模块(文件)的字典。
-
B (Built-in): Python 内置符号的字典。
这就是为什么你开头给出的代码中 print = log_print 能生效:
-
你在 Global 字典中插入了一个 Key 为
"print",Value 为log_print函数对象的条目。 -
当代码后续调用
print()时,Python 先查 Global 字典,找到了你的版本,于是屏蔽了 Built-in 字典里的原始版本。
类与继承的本质:字典的链式查找
在 Python 中,类本身也是一个对象,它也有自己的 dict,用来存储类变量和方法。
方法调用是怎么发生的?
当你调用 u.say_hello() 时:
-
先在实例
u.dict里找(通常找不着方法,只找得着属性)。 -
去
User.dict(类字典)里找。 -
如果没找到,去父类的
dict里找(按照 MRO 顺序)。
内存模型:一切皆对象(PyObject)
在 Python 的 C 实现(CPython)中,所有的东西——无论是整数、字符串还是函数——本质上都是一个 PyObject 结构体。
函数在内存中是什么?
当你定义 def log_print(): ... 时,Python 解释器会在堆内存中创建一个类型为 PyFunctionObject 的对象。
-
Java 视角:方法是字节码中的一段指令映射。
-
Python 视角:函数是一个实例化的对象,就像你在 Java 里
new出来的HashMap一样。它有自己的内存地址,有属性(比如name),甚至可以动态添加属性。
Main函数
入口
*if* __name__ == "__main__":
parser = argparse.ArgumentParser(*description*='IMO Problem Solver Agent (SDK Version)')
parser.add_argument('problem_file', *nargs*='?', *default*='problem_statement.txt',
*help*='Path to the problem statement file (default: problem_statement.txt)')
parser.add_argument('--log', '-l', *type*=str, *help*='Path to log file (optional)')
parser.add_argument('--other_prompts', '-o', *type*=str, *help*='Comma-separated other prompts (optional)')
parser.add_argument("--max_runs", '-m', *type*=int, *default*=10, *help*='Maximum number of runs (default: 10)')
args = parser.parse_args()
max_runs = args.max_runs
other_prompts = []
*if* args.other_prompts:
other_prompts = args.other_prompts.split(',')
print(">>>>>>> Other prompts:")
print(other_prompts)
Arguments模块
argparse 是 Python 标准库中处理命令行参数的利器,相当于 Java 中的 JCommander 或 Commons CLI。
实例化解析器
parser = argparse.ArgumentParser(description='...')
- 定义一个解析器对象,
description用于在用户输入-h或--help时显示的帮助文本。
这段代码展示了四种不同的参数定义方式:
- 位置参数 (Positional Argument):
parser.add_argument('problem_file', nargs='?', default='...')
- 没有
--前缀。 nargs='?':表示该参数是可选的(0 个或 1 个)。default:如果用户没传,就用这个默认值。
- 可选参数 + 指定类型 (Typed Argument):
parser.add_argument("--max_runs", '-m', type=int, default=10)
--前缀。意味参数可选type=int:argparse会自动尝试将输入字符串转换为int。如果用户输入了非数字,会直接报错并显示帮助信息。
一些关键字
Glogal
数据结构与使用
变量的类型无需显示声明
无基础数据类型
在 Java 中,int a = 5; 占用 4 字节栈空间。 在 Python 中,a = 5 实际上是:
-
创建一个
PyLongObject对象,存放在堆上。 -
a是一个引用,指向这个对象。 由于 Python 对小整数(-5 到 256)进行了****对象池**(Integer Interning)**缓存,所以性能损失被降到了最低。
str
普通用法
https://zhuanlan.zhihu.com/p/662644470
创建字符串有4种方式 ,示例如下:
str1 = 'This is a string. We built it with single quotes.'
str2 = "This is also a string, but built with double quotes."
str3 = '''This is built using triple quotes,
so it can span multiple lines.'''
str4 = """This too is
a multiline onebuilt
with triple double-quotes."""
print(f'1、{str1}')
print(f'2、{str2}')
print(f'3、{str3}')
join函数
memory_lines = ["用户问了天气", "机器人回答了晴天", "用户说了谢谢"]
memory_context = "\n".join(memory_lines)
变量 memory_context 的结果会变成一个单一的字符串:
用户问了天气
机器人回答了晴天
用户说了谢谢
为什么这么做 在开发 AI 或聊天机器人(Context Window 管理)时,这个操作非常常见:
- 从列表到文本:程序通常用列表(List)来动态存储每一句对话,因为列表方便添加(
append)数据。 - 送入模型解析:大模型(如 Gemini)通常接收的是一段连续的长文本(String),而不是列表。
- 格式化:通过
"\n".join(),你把零散的对话记录转换成了模型能够理解的、带格式的“上下文段落”。
常见变体 你可以根据需要更换分隔符:
- 空格连接:
" ".join(words)—— 将单词连成句子。 - 逗号连接:
",".join(tags)—— 生成 CSV 格式或标签列表。 - 双换行连接:
"\n\n".join(paragraphs)—— 在段落之间留出空行
f-string 格式化
user_prompt = f"Input:\n{parsed_messages}"
f"...":表示这是一个格式化字符串。
{parsed_messages}:这是一个占位符。Python 会把变量 parsed_messages 的实际内容填入到这个位置。
\n:代表换行。
json操作
- 序列化,将list/dict转为json==》json.dumps
- 在 Python 中,我们经常处理字典(dict),但如果你想把这些数据发送给网页前端、写入文本文件或者通过 API 传输,你就需要把它变成标准化的 JSON 字符串。
import json
# 这是一个 Python 字典
data = {
"name": "张三",
"age": 25,
"is_student": False
}
# 使用 dumps 将其转换为 JSON 字符串
json_string = json.dumps(data, ensure_ascii=False)
print(json_string)
# 输出: {"name": "张三", "age": 25, "is_student": false}
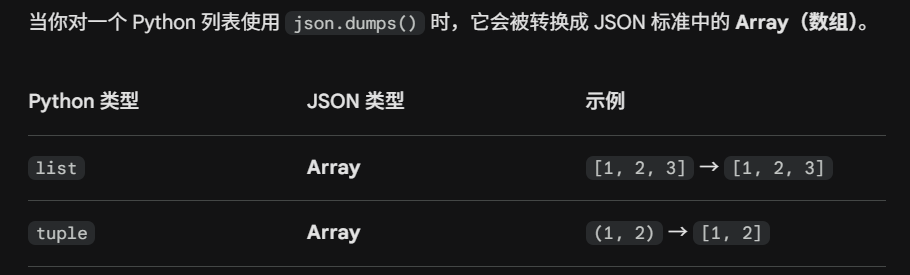
list []
它可以同时存储不同类型:my_list = [1, "Hello", [1, 2]]。
它支持极其强大的**切片(Slicing)**操作:my_list[1:3]。
底层实现:连续的指针数组,扩容策略比 Java 更激进,以减少 realloc 的次数。
list1 = ['physics', 'chemistry', 1997, 2000]
list2 = [1, 2, 3, 4, 5 ]
list3 = ["a", "b", "c", "d"]
增
list1.append("sad")
删
del list1[2]
查
list1[2]
list2[1:5]
Tuple() -list的进阶
-
不可变性:一旦创建,不能增删改(底层内存分配后固定)。
-
可哈希:正因为不可变,它可以作为
dict的 Key。 -
性能:比
list更轻量
# 1. 定义 (使用圆括号)
point = (10, 20)
user_info = ("Alice", 25, "Engineer")
# 2. 访问 (通过下标)
print(point[0]) # 10
# 3. 解构 (Unpacking) - Python 的杀手锏
# 相当于 Java 里把对象字段自动赋值给局部变量
name, age, job = user_info
print(f"Name: {name}, Age: {age}")
# 4. 只有 1 个元素的元组 (必须加逗号,否则会被当作括号运算符)
single = (1,)
字典dict{}
特点
-
键值对:Key 必须是不可变类型(str, int, tuple)。
-
有序性:Python 3.7+ 默认保留插入顺序。
底层结构
在传统的哈希表(如 Java 8 之前的 HashMap 或旧版 Python)中,哈希表是一个巨大的数组,每个槽位(Bucket)直接存储 Key-Value 对。如果哈希表很空,会浪费大量内存。
现代 Python(3.6+)引入了 “紧凑字典”(Compact Dict) 概念,将内存拆分为两个数组:
-
Indices Array(索引数组):一个存储整数的小数组,充当哈希表。
-
Entries Array(实体数组):一个紧凑的数组,按插入顺序存储具体的
hash,key,value。
工作流程:
当你要查找 d["name"] 时:
-
计算
"name"的哈希值。 -
通过
hash & (mask)找到 Indices Array 中的下标。 -
取出该下标对应的值(比如
2)。 -
去 Entries Array 的索引
2位置直接获取数据。
Java 对比:Java HashMap 使用 Node 数组 + 链表/红黑树。Python 通过维护 Entries 数组的顺序,不仅节省了内存(不存储空槽的 KV 指针),还顺带实现了 Preserve Insertion Order(保留插入顺序)。
>>> tinydict = {'a': 1, 'b': 2, 'b': '3'}
>>> tinydict['b']
'3'
>>> tinydict
{'a': 1, 'b': '3'}
用法
# 1. 定义 (使用花括号和冒号)
scores = {"Math": 95, "English": 88}
# 2. 访问与修改
scores["Math"] = 98 # 修改
scores["Science"] = 90 # 新增
# 3. 安全访问 (类似 Java 的 Optional 或 getOrDefault)
# 直接用 scores["History"] 如果不存在会报 KeyError
history = scores.get("History", 0) # 找不到返回默认值 0
# 4. 遍历 (非常 Pythonic)
for key, value in scores.items():
print(f"Subject: {key}, Score: {value}")
# 5. 合并字典 (Python 3.9+)
new_scores = scores | {"Art": 85}
# 删
del tinydict['Name'] # 删除键是'Name'的条目
tinydict.clear() # 清空字典所有条目
del tinydict # 删除字典
# 查/增
tinydict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
tinydict['Age'] = 8 # 更新
tinydict['School'] = "RUNOOB" # 添加
Set{}
特点
-
唯一性:自动去重。
-
无序性:元素没有下标。
-
集合运算:原生支持交、并、差集。
# 1. 定义 (使用花括号)
fruits = {"apple", "banana", "orange"}
# 注意:空集合必须用 set(),因为 {} 是空字典
empty_set = set()
# 2. 快速去重
ids = [1, 2, 2, 3, 4, 4, 4]
unique_ids = set(ids) # {1, 2, 3, 4}
# 3. 集合运算 (Java 需要调用多个方法,Python 只需符号)
a = {1, 2, 3}
b = {3, 4, 5}
print(a | b) # 并集 (Union): {1, 2, 3, 4, 5}
print(a & b) # 交集 (Intersection): {3}
print(a - b) # 差集 (Difference): {1, 2}
None
Java 的 null 是一个特殊的关键字。Python 的 None 是一个真实的单例对象(属于 NoneType 类)。
- 检查是否为空的惯用法是
if x is None:而不是if x == None:。
推导式 (Comprehension)
类似于stream
函数方法
定义
- 指定参数:
def function_name(parameter1, parameter2):
# 这里是缩进代码块(没有花括号!)
return value
- 类型提醒
- 严格模式:指定输入和输出的数据类型
def square(number: int) -> int:
return number*number
注意:这里用到了python的类型提醒,表示该函数的输入为int型,输出也为int型
def call_gemini_api(
system_instruction: str | None,
contents: list,
verbose: bool = True
) -> str | None:
#XX 函数内容
def: 关键字,相当于 Java 的 public static(在模块级别定义时)。
system_instruction: str | None: 参数类型注解。str | None 是 Python 3.10+ 的语法,相当于 Java 的 String(但显式标注了可以是 null)。
verbose: bool = True: 默认参数。调用时如果不传这个参数,它默认为 True。这在 Java 中通常需要通过方法重载(Overloading)来实现。
-> str | None: 返回值注解。说明该函数要么返回字符串,要么返回 None (Java 的 null)。
可变参数函数定义
位置可变参数(*args)和关键字可变参数(**kwargs)。
*args
***args**:对应 Java 的可变参数 String... args,
*args 会将所有“按顺序传入”的多余参数打包成一个 **Tuple(元组)**
def sum_all(*numbers):
# numbers 在这里是一个元组,比如 (1, 2, 3)
total = 0
for n in numbers:
total += n
return total
print(sum_all(1, 2, 3, 4)) # 输出 10
**kwargs
****kwargs**:Java 没有直接对应物,它接收**键值对(Named Arguments)**,它
会将所有“带名字传入”的参数打包成一个 **Dict(字典)**
def print_info(**info):
# info 在这里是一个字典,比如 {"name": "Alice", "age": 25}
for key, value in info.items():
print(f"{key} == {value}")
print_info(name="Alice", age=25, job="Manager")
同时使用
它使用了 “完全透传(Full Forwarding)” 模式。
由于它不知道原生的 print 函数到底会被怎么调用(可能有人传 print("a", "b"),也可能有人传 print("a", end="")),通过同时接收 *args(捕获内容)和 **kwargs(捕获配置如 end, file, sep),它实现了对原生 print 接口的 100% 完美模拟。
def log_print(*args, **kwargs):
original_print(*args, **kwargs)
# ... 后续逻辑
参数解包(Unpacking):逆向操作
这是 Python 最骚的操作。如果你手里已经有一个 List 或 Dict,你可以用 * 或 ** 将它们“打散”传给函数。
def my_func(a, b, c):
print(a, b, c)
# 1. 列表解包
params_list = [1, 2, 3]
my_func(*params_list) # 等价于 my_func(1, 2, 3)# 2. 字典解包
params_dict = {"a": 1, "b": 2, "c": 3}
my_func(**params_dict) # 等价于 my_func(a=1, b=2, c=3)
底层原理
从底层来看,这涉及到 Python 虚拟机的 栈操作:
-
打包(Packing):当调用函数时,Python 解释器会先识别出固定参数。剩下的位置参数会被压入一个
PyTupleObject,剩下的关键字参数会被压入一个PyDictObject。 -
赋值:将这两个对象分别赋值给函数局部命名空间里的
args和kwargs变量。
函数即对象
在 Java 中,方法(Method)依附于类(Class),你不能直接把 public void myMethod() 赋值给一个变量。但在 Python 中,函数即对象。
在 Python 中,变量只是一个指向对象的标签。
在 Python 中,通过修改符号表,你只用一行代码就完成了整个模块的 AOP(面向切面编程)。
_log_file = None # 1. 在全局字典中定义一个 Key,初始为 None
original_print = print # 2. 备份:将内置 print 的对象引用存起来
def log_print(*args, **kwargs): # 3. 定义一个新函数对象
"""
自定义打印函数,同时输出到 stdout 和日志文件。
"""
original_print(*args, **kwargs) # 4. 透传:调用备份的原生函数
if _log_file is not None:
# 5. 序列化:将所有位置参数转为字符串并拼接
message = ' '.join(str(arg) for arg in args)
_log_file.write(message + '\n')
_log_file.flush()
print = log_print # 6. 劫持:改变全局字典中 'print' 的指向
类结构
类结构
在 Java 中,this 是隐式关键字。在 Python 中,self 必须显式作为第一个参数传入方法。
class Dog:
# 相当于 Java 的构造函数
def __init__(self, name):
self.name = name # 实例变量:存储在实例的 __dict__ 中
# 实例方法
def bark(self):
print(f"{self.name} says woof!")
- 不需要属性声明
不需要在类顶端声明 private String name;。只要在 init 中赋值给 self.xxx,属性就“诞生”了。
-
init()
-
非必须
-
它不是真正的构造函数(
new才是),它负责初始化已创建的实例。类的初始化(例如属性赋值) -
在类一实例化的时候便会执行
-
Self
-
不是关键字,只是个约定俗成的变量名。调用
my_dog.bark()时,Python 自动将my_dog传给第一个参数。 -
Python setattr() 函数
类的继承
-
可以继承多个父类
-
可以重写父类方法
-
**通过super() **调用父类方法
-
调用本地的属性,使用 self.name
-
父类中有init方法时,子类必须为父类的init方法中的 全部属性 赋值
class Parent1:
def greet(self):
print("Hello from Parent1")
class Parent2:
def greet(self):
print("Hello from Parent2")
class Child(Parent1, Parent2):
def greet(self):
super().greet() *# 调用父类方法*
print("Hello from child")
child = Child()
child.greet() # 输出: Hello from Parent1 (根据继承顺序)
class Parent:
def __init__(self, name):
self.name = name
class Child(Parent):
def __init__(self, name, age):
super().__init__(name) # 调用父类的初始化方法
self.age = age
child = Child("Alice", 10)
print(child.name) # 输出: Alice
print(child.age) # 输出: 10
抽象类
from abc import ABC, abstractmethod
# 定义抽象基类
class Shape(ABC):
@abstractmethod
def area(self):
"""计算面积"""
pass
@abstractmethod
def perimeter(self):
"""计算周长"""
pass
# 子类必须实现所有抽象方法
class Rectangle(Shape):
def __init__(self, width, height):
self.width = width
self.height = height
def area(self):
return self.width * self.height
def perimeter(self):
return 2 * (self.width + self.height)
# 实例化子类
rect = Rectangle(5, 10)
print(rect.area()) # 输出: 50
print(rect.perimeter()) # 输出: 30
# 尝试实例化抽象类会报错
# shape = Shape() # TypeError: Can't instantiate abstract class Shape with abstract methods area, perimeter
代码分支结构
try, except, else, 和 finally,raise
example
捕获所有异常
try:
result = 10 / 0
except Exception as e:
print(f"发生了一个错误:{e}")
try:
# 可能会发生异常的代码
result = 10 / 0 # 尝试对数字进行除零操作,会触发 ZeroDivisionError 异常
except ZeroDivisionError:
# 处理特定类型异常的代码块
print("除零错误发生了!")
else:
# 没有发生异常时执行的代码块
print("没有发生异常!")
finally:
# 无论是否有异常都会执行的清理代码块
print("无论是否有异常,这里都会执行!")
try-except的优雅使用:
file = None # 先将 file 变量初始化为 None
try:
file = open('file.txt', 'r')
content = file.read()
number = 1 / 0 # 这里可能会触发 ZeroDivisionError
except FileNotFoundError:
print("文件未找到!")
except ZeroDivisionError as e:
print(f"发生除零错误:{e}")
except Exception as e:
print(f"发生其他类型的异常:{e}")
finally:
if file is not None: # 在关闭文件之前验证文件句柄的存在
file.close()
with、match 和 else块
with -上下文管理器(Context Manager)
原理
https://zhuanlan.zhihu.com/p/666349407
with 是 Python 中用于资源管理的关键字,它提供了一种简洁的方式,确保在使用完资源后自动进行清理(如关闭文件、释放锁、断开连接等)。这种机制基于上下文管理器(context manager)协议。
with操作可以自动执行代码前后设置的特定的设置和清理
一个类如果定义了 enter 和 exit 方法,其实例就可以作为上下文管理器。
class MyContext:
def __enter__(self):
print("进入上下文")
return self # 可以返回任何对象,供 as 子句使用
def __exit__(self, exc_type, exc_val, exc_tb):
print("退出上下文")
# 返回 True 表示异常已被处理,不再向外抛出;返回 False 则继续抛出
return False
with MyContext() as obj:
print("执行中")
# 如果这里发生异常,__exit__ 仍然会被调用
文件操作:
- 在处理文件读写时,使用
with语句可以确保在退出代码块时文件会被正确关闭,即使发生异常也不会影响文件的关闭操作。例如:
try:
with open('file.txt', 'r') as file:
content = file.read()
# 其他文件操作
except FileNotFoundError:
print("文件未找到!")
except IOError as e:
print(f"文件操作发生异常:{e}")
else:
print("文件操作成功完成!")
具体来说,当进入 with 语句块时,open 函数会被调用以打开文件,返回的文件对象会被传递给上下文管理器,而上下文管理器会负责捕获并处理可能发生的异常,比如文件未找到或者其他 I/O 错误,然后在退出代码块时正确关闭文件。因此,如果在打开文件的过程中出现异常,文件句柄根本就没有被创建,也就不需要额外的操作去关闭文件。
这种结构的好处是,无论文件操作是否成功,上下文管理器都会在退出代码块时正确关闭文件,避免了忘记手动关闭文件句柄造成资源泄漏的问题。
数据库操作:
用Python的数据库模块来处理数据库连接时,可以使用with语句来自动管理资源,包括数据库连接。下面是一个经典示例代码,用于演示如何利用with语句处理数据库连接并处理错误:
import sqlite3
try:
# 尝试连接数据库
conn = sqlite3.connect('example.db')
cursor = conn.cursor()
# 在这个代码块中,已成功建立数据库连接并创建游标
cursor.execute('SELECT * FROM table_name')
rows = cursor.fetchall()
for row in rows:
print(row)
except sqlite3.Error as e:
# 处理数据库操作可能出现的异常
print(f"数据库操作发生异常:{e}")
finally:
# 无论是否发生异常,都需要确保关闭数据库连接
if 'cursor' in locals():
cursor.close()
if 'conn' in locals():
conn.close()
在这个例子中,我们首先使用with语句创建了一个数据库连接connection。然后在with代码块内部,我们使用了try...except结构来捕获可能出现的数据库错误。在try块中,我们执行了一个简单的查询,并在except块中处理任何可能出现的sqlite3.Error。在with代码块结束时,Python会自动关闭数据库连接,无论是否发生了异常。
使用with语句可以确保资源在使用完成后被正确释放,同时通过try...except可以捕获并处理可能的错误,使得代码更加健壮和可靠。
网络连接:
处理网络连接时,使用上下文管理器可以确保连接在使用后被正确关闭,并且能够处理可能发生的网络错误。以下是一个经典案例,演示如何使用上下文管理器来管理网络连接:
import socket
# 定义服务器地址和端口
server_address = ('127.0.0.1', 8888)
# 创建一个套接字对象
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
try:
# 连接到服务器
s.connect(server_address)
# 发送数据
message = 'Hello, server!'
s.sendall(message.encode('utf-8'))
# 接收数据
data = s.recv(1024)
print('Received:', data.decode('utf-8'))
except socket.error as e:
# 处理网络错误
print("网络错误:", e)
在这个例子中,我们首先创建了一个套接字对象,然后使用with语句来管理这个套接字对象s。在with代码块内部,我们尝试连接到服务器并发送数据,同时使用try...except结构来捕获可能发生的网络错误。无论是否发生异常,with代码块结束时都会自动关闭套接字连接,确保资源得到正确释放。
这个例子展示了如何使用上下文管理器来管理网络连接,确保连接在使用完成后被正确关闭,并处理可能出现的网络错误。这种方式使得网络编程更加健壮和可靠。
多线程同步:
当在多线程环境中使用锁时,有时候需要在获取锁的过程中处理可能出现的异常。这时可以结合 try 和 except 语法来进行线程锁的管理。下面是一个经典的例子:
假设我们有一个共享资源 shared_resource,多个线程需要对其进行操作,为了确保线程安全,我们使用 threading.Lock 来创建一个锁并在需要的地方加锁和解锁。
import threading
shared_resource = 0
lock = threading.Lock()
def thread_function():
global shared_resource
try:
with lock:
# 在这个代码块中,锁已经被获取
shared_resource += 1
except Exception as e:
print(f"发生异常:{e}")
finally:
# 无论是否发生异常,都需要确保释放锁
lock.release()
# 创建多个线程并启动
threads = []
for _ in range(5):
t = threading.Thread(target=thread_function)
threads.append(t)
t.start()
# 等待所有线程结束
for t in threads:
t.join()
print("最终的 shared_resource 值为:", shared_resource)
在这个例子中,我们定义了一个 thread_function,在其中我们使用 with lock 结构来获取锁,然后对共享资源 shared_resource 进行操作。如果在获取锁或对共享资源进行操作的过程中发生异常,我们可以在 except 块中捕获异常并进行相应的处理。最后,在 finally 块中确保释放锁,以确保其他线程能够继续访问共享资源。
通过结合 try 和 except 语法,我们可以在多线程程序中更安全地管理锁的获取和释放,并对可能出现的异常进行处理,确保程序的稳定性和可靠性。
内存分配:
存分配时,一种常见的情况是使用动态内存分配来创建和管理资源。在 Python 中,可以使用内置的 ctypes 模块来进行内存分配和释放。以下是一个简单的示例:
import ctypes
try:
# 尝试分配内存
buffer_size = 10
buffer = ctypes.create_string_buffer(buffer_size)
# 在这个代码块中,已成功分配了内存
ctypes.memset(buffer, 0, buffer_size) # 对内存进行初始化(可选操作)
except MemoryError as e:
# 处理内存分配可能出现的异常
print(f"内存分配发生异常:{e}")
finally:
# 无论是否发生异常,都需要确保释放已分配的内存
if 'buffer' in locals():
del buffer
在这个案例中,我们尝试使用 ctypes 模块分配一块内存,并对其进行操作。在try块中,我们尝试分配内存并进行相关操作。如果在这个过程中发生了内存分配异常(MemoryError),我们将在except块中捕获异常并进行相应处理。最后,在finally块中,我们确保释放了已经分配的内存,以避免内存泄漏问题。
通过使用try-except结构,我们能够在内存分配过程中处理可能出现的异常,并且在finally块中确保了已分配的内存得到了正确释放,从而避免资源泄露问题。
自定义上下文管理器
import sqlite3
class DatabaseConnection:
def __init__(self, db_name):
self.db_name = db_name
self.connection = None
def __enter__(self):
self.connection = sqlite3.connect(self.db_name)
return self.connection
def __exit__(self, exc_type, exc_value, traceback):
self.connection.close()
# 使用自定义的数据库连接上下文管理器
with DatabaseConnection('example.db') as conn:
cursor = conn.cursor()
cursor.execute("CREATE TABLE IF NOT EXISTS users (id INTEGER PRIMARY KEY, name TEXT)")
在这个示例中,我们定义了一个名为 DatabaseConnection 的类,它实现了 enter 和 exit 方法。在 enter 方法中,我们建立了与数据库的连接并返回连接对象,以便在 with 语句块中使用。在 exit 方法中,我们关闭了数据库连接。
这个例子展示了如何使用自定义上下文管理器来管理数据库连接,确保在代码块结束时正确关闭连接,无论是否发生异常。
除了文件操作和数据库连接之外,自定义上下文管理器还可以用于各种资源的管理,例如网络连接、线程锁等。通过使用自定义上下文管理器,你可以确保资源的获取和释放都能得到正确管理,使得代码更加健壮和可维护。
match-else
https://zhuanlan.zhihu.com/p/677755331
https://blog.csdn.net/xyh2004/article/details/140405858
match-case只有OR模式,没有AND模式
match subject:
case <pattern_1>:
<action_1>
case <pattern_2>:
<action_2>
case <pattern_3>:
<action_3>
case _:
<action_wildcard>
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
def where_is(point):
match point:
case Point(0, 0):
print("Origin")
case Point(0, y):
print(f"Y={y}")
case Point(x, 0):
print(f"X={x}")
case Point(x, y):
print(f"X={x}, Y={y}")
case _:
print("Not a point")
python装饰器
装饰器,顾名思义,就是增强函数或类的功能的一个函数。
@property
@property 装饰器用于将类的方法转换为属性,使得可以像访问属性一样访问方法。这使得代码更加简洁和直观。
class Person:
def __init__(self, name, age):
self._name = name
self._age = age
@property
def name(self):
return self._name
@property
def age(self):
return self._age
@age.setter # 设置属性的setter方法
def age(self, value):
if value < 0:
raise ValueError("Age cannot be negative")
self._age = value
# 使用示例
p = Person("Alice", 30)
print(p.name) # 输出: Alice
print(p.age) # 输出: 30
p.age = 35 # 通过setter方法设置年龄
print(p.age) # 输出: 35
# p.age = -5 # 会抛出 ValueError
@classmethod
@classmethod 装饰器用于定义类方法。类方法的第一个参数必须是表示类本身的 cls,而不是实例。类方法通常用于创建类的工厂方法。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
@classmethod
def from_birth_year(**cls**, name, birth_year):
return cls(name, 2023 - birth_year)
# 使用示例
p1 = Person("Alice", 30)
p2 = Person.from_birth_year("Bob", 1990)
print(p1.name, p1.age) # 输出: Alice 30
print(p2.name, p2.age) # 输出: Bob 33
@staticmethod
@staticmethod 装饰器用于定义静态方法。静态方法不依赖于类或实例,它们类似于普通函数,但在类的命名空间中。静态方法通常用于实现逻辑上与类相关但不需要访问类或实例的功能。
class Math:
@staticmethod
def add(x, y):
return x + y
@staticmethod
def subtract(x, y):
return x - y
# 使用示例
print(Math.add(5, 3)) # 输出: 8
print(Math.subtract(5, 3)) # 输出: 2
@abstratmethod
@abstractmethod 装饰器用于定义抽象方法,这些方法必须在子类中实现。这个装饰器通常与 abc 模块中的 ABC 类一起使用。
from abc import ABC, abstractmethod
class Animal(ABC):
@abstractmethod
def make_sound(self):
pass
class Dog(Animal):
def make_sound(self):
return "Woof"
class Cat(Animal):
def make_sound(self):
return "Meow"
# 使用示例
dog = Dog()
cat = Cat()
print(dog.make_sound()) # 输出: Woof
print(cat.make_sound()) # 输出: Meow
# animal = Animal() # 不能实例化抽象类,会抛出 TypeError
@dataclass
语法点:使用了 @dataclass 装饰器。
分析:它自动为类生成 init、repr 等特殊方法。这意味着你不需要手动写 self.model_name_or_path = model_name_or_path。这种写法极大地减少了样板代码,提高了可读性。
自定义装饰器
自定义日志装饰器
import functools
def log_calls(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
print(f"Calling {func.__name__} with args={args} and kwargs={kwargs}")
result = func(*args, **kwargs)
print(f"{func.__name__} returned {result}")
return result
return wrapper
# 使用示例
@log_calls
def add(x, y):
return x + y
@log_calls
def greet(name, greeting="Hello"):
return f"{greeting}, {name}!"
print(add(3, 5)) # 调用 add(3, 5)
print(greet("Alice")) # 调用 greet("Alice")
print(greet("Bob", greeting="Hi")) # 调用 greet("Bob", greeting="Hi")
自定义计时装饰器
import functools
import time
def timer(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
elapsed_time = end_time - start_time
print(f"{func.__name__} executed in {elapsed_time:.4f} seconds")
return result
return wrapper
# 使用示例
@timer
def slow_function(duration):
time.sleep(duration)
return "Done"
print(slow_function(2)) # 调用 slow_function(2)
迭代器和生成器
https://www.bilibili.com/video/BV1sS4y1b7qb/?spm_id_from=333.1387.favlist.content.click
迭代器
可迭代对象都实现了 _iter_接口
迭代器中含有两个函数 iter() next()
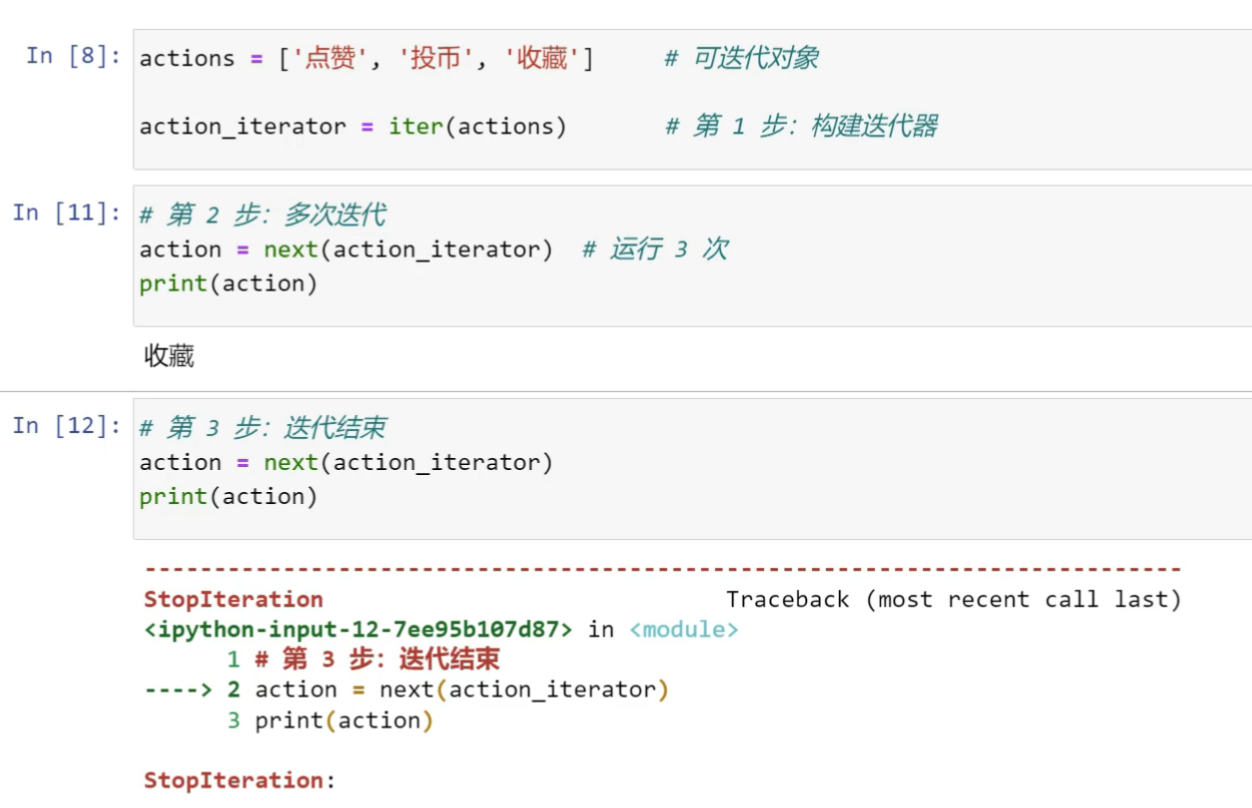

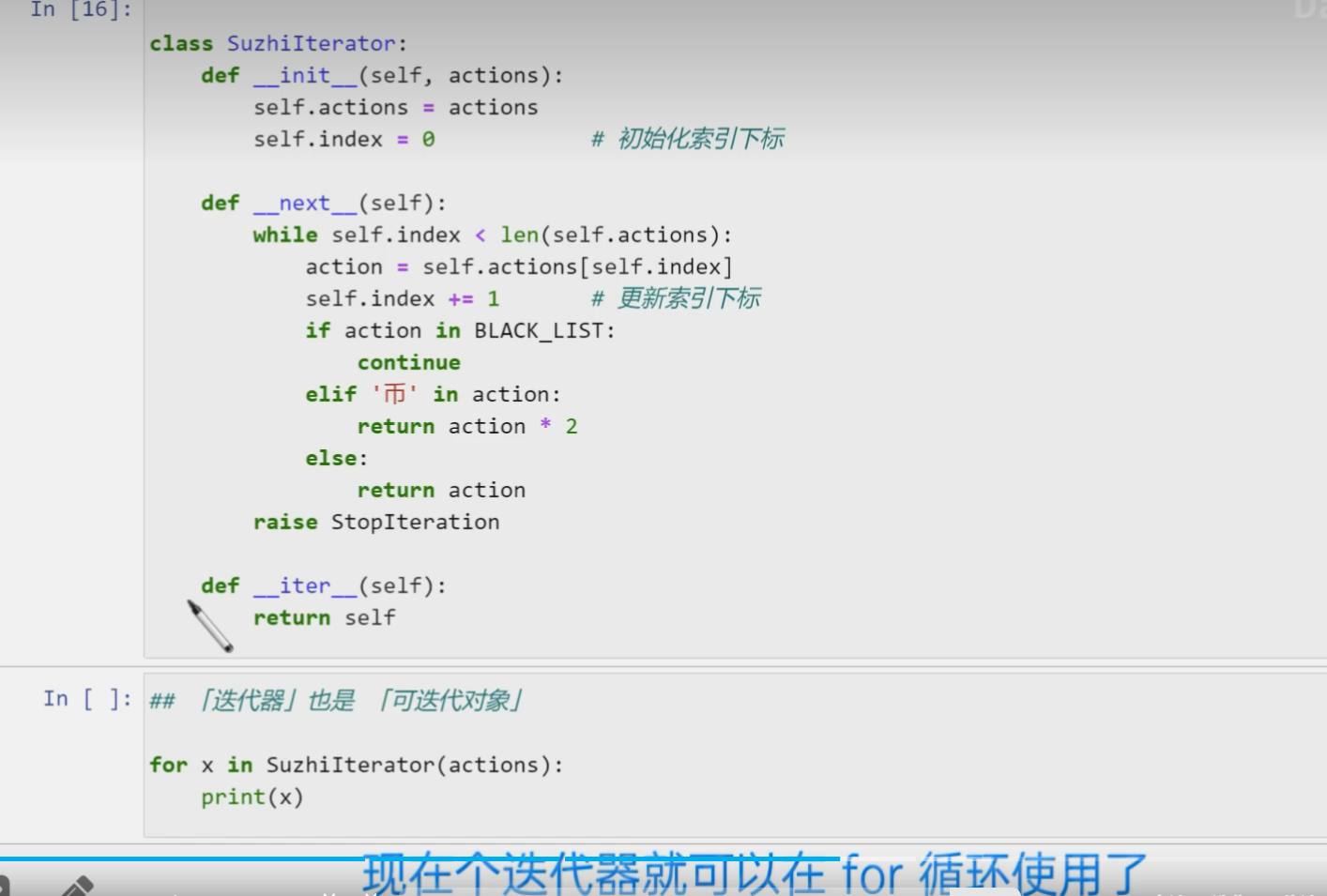




迭代器应用:数据管道


迭代器应用:数据生成器
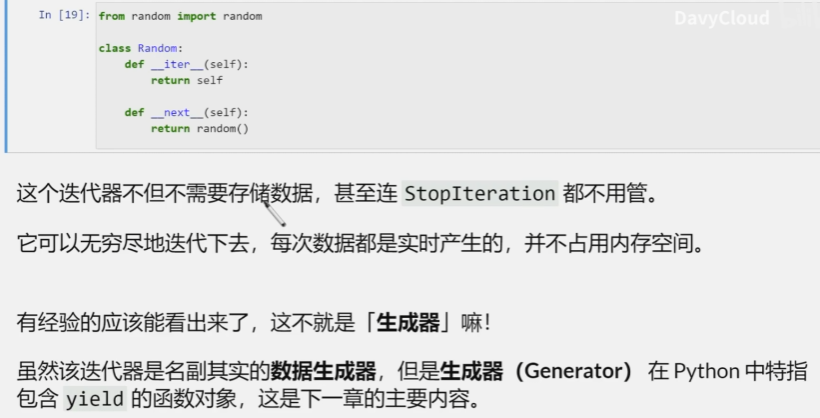
生成器




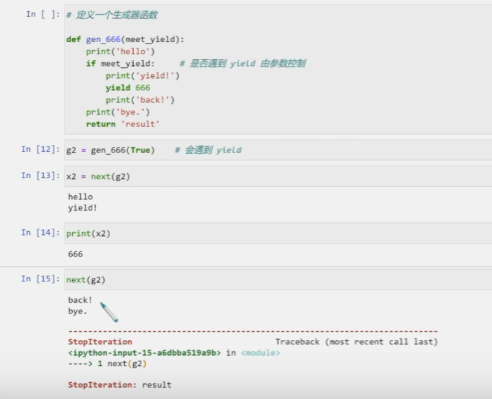



yield
Python 3.5 之后引入了 async/await,协程的实现不再直接依赖 yield,但底层原理仍源于生成器。await 在底层相当于 yield from,而 async def 函数会被编译为带有特定标志的生成器。
协程asyncio
-
协程,又称微线程,英文名
Coroutine,是运行在单线程中的“并发”,协程相比多线程的一大优势就是省去了多线程之间的切换开销,获得了更高的运行效率。Python中的异步IO模块asyncio就是基本的协程模块。 -
协程(Coroutine)是 Python 中实现并发的一种重要方式。它允许我们在单线程内通过主动让出控制权来切换任务,从而实现类似多线程的并发效果,但开销远小于线程,非常适合 I/O 密集型场景。
-
协程与线程的区别:
- 线程是操作系统级别的抢占式调度,上下文切换开销大。
- 协程是用户态的非抢占式调度,通过
await主动让出,切换极快。
定义协程函数:
async
async 关键字创建一个协程。
-
协程函数:用
async def定义的函数,调用它不会立即执行,而是返回一个协程对象class coroutine。 -
asyncio.run()被设计为asyncio程序的主要入口点。仅执行一个协程,该协程可能会调用程序中的其他协程和函数。
import asyncio
# 定义一个协程函数
async def say_hello():
print("Hello")
await asyncio.sleep(1) # 模拟 I/O 等待,主动让出控制权
print("World")
# 运行协程
asyncio.run(say_hello())
#say_hello 是一个协程函数,调用它不会执行,而是返回一个协程对象。
#asyncio.sleep(1) 也是一个协程,await 会挂起当前协程,直到 sleep 完成(即 1 秒后)。
#asyncio.run() 会创建一个事件循环,并运行传入的协程直到完成。
在Jupyter笔记本中,你可以直接使用await来运行异步代码,而不需要使用asyncio.run()。如果你是在一个脚本中,确保整个脚本的执行入口是异步的,并且使用if name == "__main__": asyncio.run(main())来启动事件循环。
await
await 关键字指的是暂停当前协程的执行,等待调用的协程返回结果再继续执行。 await** 关键字后面是对协程的调用,**如下所示:
result = await my_coroutine()
await** 关键字导致 my_coroutine() 执行,等待代码完成并返回结果****。**
需要注意的是 await 关键字仅在协程内部有效。换句话说,您必须在async def函数中(协程内)使用 await 关键字。
网络请求
在处理网络请求时,协程允许你并发地发送多个请求并等待它们的响应,而不会阻塞主线程。这对于开发高效的网络爬虫或处理大量并行API调用的服务尤为重要。
示例代码概念
import asyncio
import aiohttp
async def fetch_url(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.text()
async def main():
urls = ["http://example.com", "http://example.org", "http://example.net"]
tasks = [fetch_url(url) for url in urls]
pages = await asyncio.gather(*tasks)处理获取的页面数据
asyncio.run(main())
真正的多并发task & Gather
协程的真正威力在于可以同时等待多个操作,通过 asyncio.gather 或 asyncio.create_task 实现并发。
Task
为了同时运行多个异步操作,你需要使用 asyncio 库中的 Task。
Task 是 asyncio 中的一个对象,它封装了一个协程,并在事件循环中并发地运行。
import asyncio
import time
async def task(name, delay):
print(f"Task {name} 开始,等待 {delay} 秒")
await asyncio.sleep(delay)
print(f"Task {name} 完成")
return f"结果 {name}"
async def main():
# 并发运行三个协程
results = await asyncio.gather(
task("A", 2),
task("B", 1),
task("C", 3)
)
print("所有任务结果:", results)
start = time.time()
asyncio.run(main())
print(f"总耗时: {time.time() - start:.2f}秒")
在这个例子中,main 协程创建了三个任务,并且使用 asyncio.gather 来等待它们全部完成。这样,这三个协程 my_coroutine 可以并发执行,协程的优势在于它们可以在等待I/O操作(如网络请求或读写文件)完成时挂起,这时其他协程可以运行,从而提高效率和响应性,减少阻塞时间,但它们不是在不同的处理器或核心上同时运行。这种方式提高了程序的效率,特别是在处理多个IO密集型或网络请求时。(这里的asyncio.gather后面补充说明)
Gather
*asyncio.gather(tasks)
在上面的例子中,我们使用了asyncio.gather(*tasks)来等待所有任务完成。这里补充说明gather的作用以及与直接await每个任务的区别:asyncio.gather(*aws, return_exceptions=False) 是一个非常有用的函数,用于并发运行aws序列中的可等待对象。它有以下特点:
-
如果aws中的某个可等待对象是协程,它会自动被封装为一个Task。
-
如果所有可等待对象都成功完成,结果将是一个由所有返回值聚合而成的列表。结果值的顺序与aws中可等待对象的顺序相对应。
-
如果return_exceptions为False(默认),aws中第一个引发异常的可等待对象会立即将异常传播给等待gather()的任务。aws中的其他可等待对象不会被取消并将继续运行。
-
如果gather()本身被取消,那么aws中所有被提交的尚未完成的可等待对象也会被取消。
-
与之前例子中的for循环+await模式相比,使用gather的优势在于:
- 它会自动将任何协程作为任务来调度执行。如果你没有手动创建任务,那么for循环+await的方法在开始await之前根本不会运行任何任务(失去了异步处理的优势),而gather会在一开始就为所有任务创建Task。
- 当return_exceptions为False(默认)时,你能立即知道是否有错误发生;而使用循环,你可能会在某个任务失败前就已经处理了很多结果。当然,这取决于实际需求,未必总是优势。
- 你可以把gather赋值给一个变量,当发生异常时,可以通过调用gathername.cancel()来批量取消所有未完成的任务,而不需要知道具体哪些任务需要取消。
因此,简而言之,使用asyncio.gather让多个协程作为任务并发执行变得非常简单和高效,它规避了手动创建任务、管理异常、取消任务等繁琐的工作。这就是为什么在上面的例子中,当我们把任务传给gather后,异步操作才真正有效执行,而且代码也变得更加简洁。
asyncio.create_task的创建和取消。
如果感兴趣可以进一步查看:
Python asyncio.create_task(): Run Multiple Tasks Concurrently
gather在上面提到asyncio.create_task的时候提到协程创建了三个任务,并且使用 asyncio.gather 来等待它们全部完成。
现在来展开了解
gather(*aws, return_exceptions=False) -> Future[tuple[()]]
asyncio.gather() 函数有两个参数:
-
aws是一系列可等待的对象。如果aws中的任何对象是协程,则asyncio.gather()函数会自动将其调度为任务。 -
默认情况下,
return_exceptions为False。如果可等待对象中发生异常,则会立即传播到等待asyncio.gather()的任务。其他等待项目将继续运行并且不会被取消。
asyncio.gather() 将可等待结果作为元组返回,其顺序与将可等待结果传递给函数的顺序相同
如果 return_exceptions 是 True 。 asyncio.gather() 会将异常添加到结果中(如果有),并且不会将异常传播给调用者。
以下示例使用 asyncio.gather() 运行两个异步操作并显示结果:
nest_asyncio
import nest_asyncio
nest_asyncio.apply()
主要作用
nest_asyncio.apply() 的作用是允许在同一个线程中“嵌套”运行多个事件循环(Event Loop)。
在标准的 Python asyncio 设计中,一个线程在同一时间只能运行一个事件循环。如果你尝试在一个已经在运行的循环中再次调用 asyncio.run() 或启动新的循环,Python 会抛出这个经典的错误:
RuntimeError: This event loop is already running
在你的代码场景中:
-
主循环:
cmd_interactive启动了一个异步主循环_async_main_loop来监听你的键盘输入和处理消息。 -
嵌套调用:在某些复杂的环境下(比如在 Jupyter Notebook 中运行,或者某些库内部强行使用了
asyncio.run),程序会尝试开启第二个循环。 -
冲突:如果没有
nest_asyncio,程序会直接崩溃。
nest_asyncio 是如何工作的?
它通过“打补丁”(Monkey Patching)的方式修改了 Python 标准库中的 asyncio。
-
它让事件循环变得可重入(Re-entrant)。
-
当检测到已经有一个循环在运行时,它不会报错,而是巧妙地将新的任务“嵌入”到当前正在运行的循环任务队列中。
应用
Web应用和API服务
在开发Web应用和API服务时,协程允许服务器并发处理多个客户端请求。这对于构建高性能的Web服务和API非常有用,可以显著提高响应速度和吞吐量。
示例代码概念
假设使用基于协程的Web框架(如FastAPI):
pythonCopy code
from fastapi import FastAPI
import httpx
app = FastAPI()
@app.get("/data")
async def fetch_data():
async with httpx.AsyncClient() as client:
response = await client.get("https://api.example.com/data")
return response.json()
对于多智能体协同这种场景
-
使用异步或者说协程的资源开销是最低的,因为异步是单线程,无论消耗的资源或者协程切换的成本都是低于进程/线程的。
-
python 提供了足够方便的工具/语法糖来对异步进行支持,写起来就像同步代码一样简单,简化了处理并行任务和复杂工作流的编程模型
这个项目作为一个LLM (Large Language Model) API封装器的代理框架,涉及到大量的API访问请求,这正是使用异步编程的主要原因之一。在这个上下文中,异步编程的使用主要带来以下几个关键优势:
-
提高并发性:异步编程允许程序在等待API响应时不会阻塞,能够同时处理多个API请求。这对于需要与服务器频繁交互的应用来说非常重要,因为它可以显著提高应用程序的并发处理能力,从而提高整体性能和响应速度。
-
提高效率和性能:通过异步请求,程序可以在等待某个请求的响应时继续执行其他任务,而不是空闲等待。这意味着可以更有效地利用程序和服务器资源,减少等待时间,提高整体的运行效率和性能。
-
改善用户体验:对于客户端应用而言,异步编程可以让界面保持响应状态,即使后台正在处理耗时的操作。这样,用户界面不会因为一个长时间运行的任务而冻结,从而大大改善了用户体验。
-
简化复杂的网络交互:在处理复杂的网络请求和响应时,异步编程模型可以简化代码的编写。通过使用
async和await,开发者可以用近似同步的方式编写代码,而实际上代码执行是非阻塞的,这使得代码更加简洁易读,同时保持了高效的执行性能。
使用异步编程来处理API请求,意味着可以同时向LLM发送多个查询,而不必等待一个查询完成后发送下一个。这对于提高数据处理速率、减少等待时间和提升用户交互的流畅性至关重要,特别是在需要快速响应和处理大量数据的应用场景中。
因此,对于这个LLM API封装器的代理框架,异步编程不仅是提高性能和效率的技术手段,也是实现高并发、高响应性服务的关键技术选择。
更深入的协程学习请参考:
future处理python并发
Future
future 是一个在将来但不是现在返回值的对象。通常,未来对象是异步操作的结果。
例如,您可以从远程服务器调用 API,并期望稍后收到结果。 API 调用可能会返回一个 future 对象,以便您可以等待它。比如OpenAI或者微软的LLM服务,当然Agent的action除了访问这些服务还可以包括其他API比如airbnb,高德地图,墨迹天气等。
import asyncio
from asyncio import Future
async def main():
my_future = Future()
print(my_future.done()) # False
my_future.set_result('Bright')
print(my_future.done()) # True
print(my_future.result())
asyncio.run(main())
新创造的feature没有任何价值,因为它还不存在。在这种状态下,未来被认为是不完整的、未解决的或未完成的。
调用 done() 方法来检查 future 对象的状态:
It returns False. 它返回 False 。
之后,通过调用 set_result() 方法为 future 对象设置一个值:
my_future.set_result('Bright')
一旦你设定了这个值,未来就完成了。在此阶段调用 future 对象的 done() 方法将返回 True
最后,通过调用 future 对象的 result() 方法获取结果:
print(my_future.result())
你可能还疑惑以上 my_future = Future(),以及set_result()的过程似乎和源码不太一样。请看接下来的示例说明如何将 future 与 await 关键字一起使用:
from asyncio import Future
import asyncio
async def plan(my_future):
print('Planning my future...')
await asyncio.sleep(1)
my_future.set_result('Bright')
def create() -> Future:
my_future = Future()
asyncio.create_task(plan(my_future))
return my_future
async def main():
my_future = create()
result = await my_future
print(result)
asyncio.run(main())
Output: 输出:
Planning my future...
Bright
How it works.
首先,定义一个接受 future 并在 1 秒后设置其值的协程:
async def plan(my_future: Future):
print('Planning my future...')
await asyncio.sleep(1)
my_future.set_result('Bright')
其次,定义一个 create() 函数,将 plan() 协程调度为任务并返回 future 对象:
def create() -> Future:
my_future = Future()
asyncio.create_task(plan(my_future))
return my_future
第三,调用返回future的 create() 函数,使用await关键字等待future返回结果,并显示它:
async def main():
my_future = create()
result = await my_future
print(result)
在实践中,您很少需要直接创建 Future 对象。但是,您将使用从 API 返回的 Future 对象。因此,了解 Future 的工作原理非常重要。
subprocess 模块(进程)
https://www.runoob.com/w3cnote/python3-subprocess.html
subprocess 是 Python 标准库中用于创建和管理子进程的模块。它允许你在 Python 程序中执行系统命令、启动外部程序,并与它们进行输入/输出/错误流的交互。它是 os.system、os.popen 等旧接口的现代替代品,提供了更强大、更安全的进程控制能力。
-
subprocess:用于启动和管理操作系统级别的子进程,适合运行外部程序、系统命令或需要进程隔离的任务。 -
协程:用于在单线程内实现用户态的并发,适合 I/O 密集型任务(如网络请求、文件 I/O)以及需要高并发但无需多核并行计算的场景。
文件路径表示
一文搞懂Python的文件路径操作 - 碧海苍梧的文章 - 知乎 https://zhuanlan.zhihu.com/p/600048459
文件路径常识
绝对路径
- windows
-
以路径
D:\files\data\ndvi.tif为例; -
在字符串前加个字符
r,表示该字符串为原始字符串,会完全忽略所有的转义字符。例如,r"D:\files\data\ndvi.tif"; -
对转义字符进行转义,例如,
"D:\\files\\data\\ndvi.tif"; -
将分隔符替换为
/,是的,在Windows系统下,将分隔符替换为/Python也能正确识别。例如,"D:/files/data/ndvi.tif"。
- Linux和MacOS下
- 直接将路径放到单引号或者双引号里就行。
相对路径
相对路径是指以当前工作目录为参照基础,链接到目标文件资源(或文件夹)的路径。
相对路径的表示符号如下:
-
以
./开头,代表当前目录和文件目录在同一个目录里,./也可以省略不写; -
以
../开头:向上走一级,代表目标文件在当前文件所在的上一级目录; -
以
../../开头:向上走两级,代表父级的父级目录,也就是上上级目录,再说明白点,就是上一级目录的上一级目录; -
以
/开头,代表根目录。
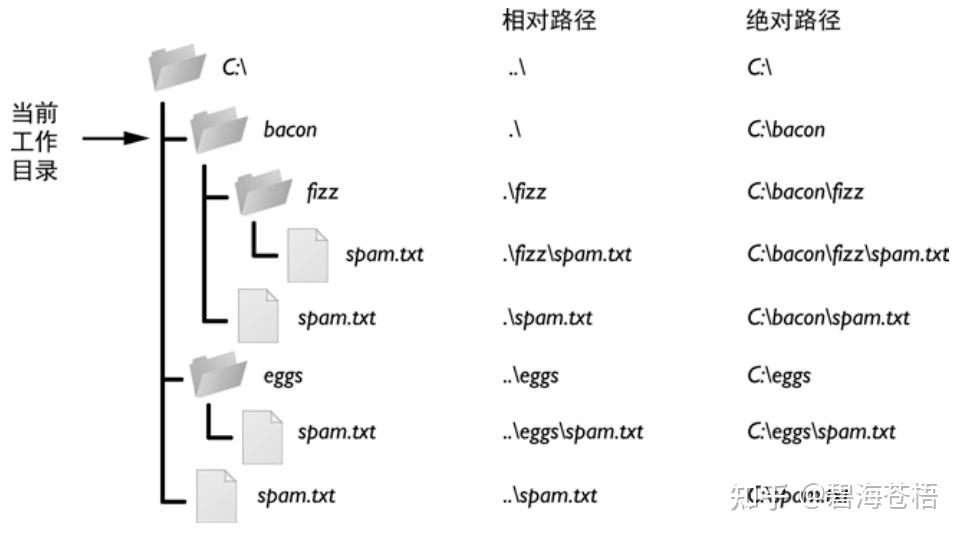
程序调用导致相对路径改变:(以调用发起方的文件相对路径为标准)
文件相对路径的dirname是调用方程序所在的路径,而不是被调用方的路径,在这儿就是a.py的路径
创建文件夹
文件写入与追加
https://blog.csdn.net/qq_35716085/article/details/135412023
path包
from pathlib import Path
核心优势:把路径当成“对象”而非“字符串”
在旧代码(os.path)中,路径只是字符串,你得不断调用函数来处理它。而使用 Path,路径是一个拥有属性和方法的对象。
from ..config.settings import get_config_dir
config_dir = get_config_dir() # 这通常返回一个 Path 对象
history_file = str(config_dir / "history")
这里的 / 运算符被 Path 类重载了,它会自动根据操作系统(Windows 用 \,Linux 用 /)选择正确的路径分隔符,避免了手动拼接字符串的麻烦。
memory_dir = str(paths.MEMORY_DIR)
如果 paths.MEMORY_DIR 是一个 Path 对象,你可以轻松地进行如下操作:
-
paths.MEMORY_DIR.parent:获取上一级目录。 -
paths.MEMORY_DIR.glob("*.json"):快速查找目录下所有的 JSON 文件。
为什么在交互式工具中很重要?
因为 Path 能够完美处理跨平台问题。你的 EvoScientist 工具可能运行在 Windows 的 PowerShell 里,也可能运行在 macOS 的终端里。使用 Path 可以确保路径解析逻辑在不同系统上表现一致,不会因为斜杠的方向写错而报错。
Pydantic库
https://zhuanlan.zhihu.com/p/696103020
是什么
Pydantic 主要用于数据验证和设置管理,在现代 Python 开发(尤其是 FastAPI 和 AI Agent 开发)中几乎是标配。
Pydantic 是 Python 中执行数据验证最流行的库。它的核心逻辑是:
-
定义规则:告诉程序,一个数据模型应该长什么样(比如:年龄必须是整数,邮箱必须有 @ 符号)。
-
自动校验:当你把数据传给它时,它会自动检查。如果不对,它会报错;如果格式稍微有点偏差(比如把字符串
"18"传给整数类型),它会尝试自动帮你修正。
核心语法解析
让我们通过一个最简单的例子来学习:
from pydantic import BaseModel, Field, EmailStr
from typing import List
# 1. 定义一个模型(继承 BaseModel)
class User(BaseModel):
id: int # 必须是整数
name: str = "匿名用户" # 字符串,默认值为"匿名用户"
age: int = Field(gt=0, lt=150) # 整数,且必须大于0,小于150
tags: List[str] = [] # 字符串列表,默认为空列表
explanation: str = Field(*description*="A brief explanation of how the code works.")
这里的关键点:
-
**继承 **
BaseModel:这是 Pydantic 的灵魂。只有继承了它,你的类才拥有自动校验数据的能力。 -
类型注解 (
: int,: str):这在 Pydantic 中不是摆设,而是强制规则。 -
Field** 函数**:它像是一个“增强插件”。gt(Greater Than): 大于lt(Less Than): 小于description: 描述这个字段是干嘛的(对 AI 开发特别有用)。
高级用法
https://mp.weixin.qq.com/s/sUAickk-fr-DJtCCSuXDqw
Annotated
Pydantic v2 结合 Annotated 可以优雅地定义领域类型:
你的项目中可能到处都有这样的字段:
-
百分比:0~1 之间的浮点数
-
非负整数
-
邮箱格式
-
两位国家代码
每次重复写 Field(ge=0, le=1) 不仅啰嗦,还容易写错。Pydantic v2 结合 Annotated 可以优雅地定义领域类型:
**from** typing **import** Annotated
**from** pydantic **import** Field
*# 定义领域类型*
Percentage = Annotated[float, Field(ge=0, le=1)]
NonNegativeInt = Annotated[int, Field(ge=0)]
EmailStr = Annotated[str, Field(pattern=r"^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$")]
*# 使用*
**class** **Discount**(BaseModel):
rate: Percentage *# 自动约束在 0~1*
max_uses: NonNegativeInt *# 不能为负*
contact: EmailStr
Pydantic 怎么用
入口处数据校验
在系统边界验证数据,别拖到业务逻辑里
我曾经见过这样的代码:从 API 拿到数据后,先存到一个临时字典,然后在业务层到处写 if 'name' in data 之类的判断。结果就是代码里散落着各种防御式检查,改了这里漏了那里
创建对象与自动转换
Pydantic 最神奇的地方在于它的容错性(数据清洗)。
# 传入的数据中,age 是字符串 "25",id 是浮点数 1.0
external_data = {
"id": 1.0,
"age": "25",
"tags": ["python", "ai"]
}
user = User(**external_data)
print(user.id) # 输出: 1 (自动从 1.0 转成了 int)
print(user.age) # 输出: 25 (自动从 "25" 转成了 int)
捕获错误
如果数据错得离谱,Pydantic 会立刻“报警”,告诉你哪里错了。
try:
User(id="abc", age=-10) # id 不是数字,age 太小了except Exception as e:
print(e) # 会详细列出 id 需要整数,age 必须大于 0
数据转换(序列化)
当你需要把数据发给前端或存入数据库时,可以一键转换:
print(user.model_dump()) # 转换成 Python 字典 (dict)
print(user.model_dump_json()) # 转换成标准的 JSON 字符串
深/浅copy
深拷贝:
state.model_copy(deep=True)
在ai中的应用
在你上一条消息提到的 DraftCode 代码中,Pydantic 充当了**“AI 指挥官”**的角色:
-
约束 AI:AI 有时会胡言乱语,但如果你给它一个 Pydantic 模型,它就必须乖乖地按照 JSON 格式返回
code和explanation。 -
自动文档:Pydantic 可以自动生成 Schema。这意味着你可以直接告诉大模型:“请按照这个 Schema 的结构给我返回数据”。

typing 包==》类型提醒:TypeDict,需要继承这个父类
TypedDict 是 Python 类型注解系统中的一个工具,它允许为字典中的键指定期望的具体类型(仅作为类型指定的作用,并不强制校验)。
from typing import TypedDict, Annotated, List
class AgentState(TypedDict):
# 使用 Annotated 和 operator.add 可以让消息不断累加,而不是覆盖
messages: Annotated[List[str], "add"]
TypedDict:定义账本的结构
在 Python 中,普通的 dict 可以放任何键值对,非常随意。但在复杂的 AI 工作流中,我们需要确切知道字典里有哪些 Key,以及 Value 是什么类型。
-
作用:它定义了一个结构化的字典。
-
为什么用它:LangGraph 要求状态必须是一个可预测的结构。使用
TypedDict后,如果你尝试访问一个不存在的键,或者存入错误类型的数据,静态检查工具(如 Pyright 或 mypy)就会报错。
List:定义数据的容器
这是 Python 标准库 typing 模块提供的泛型工具。
-
作用:明确指出这个字段是一个列表。
-
List[str]:意味着这个列表中只能存放字符串。 -
在 LangGraph 中:通常我们会存入
BaseMessage对象(来自 LangChain),用于记录对话历史。
python 原生list和 List 的区别
简单来说:list** 是运行时的“容器”,而 List 是开发时的“说明书”。**
历史背景:为什么会有两个?
在 Python 的早期版本(3.9 以前),原生的 list 不支持泛型(Generics)。
-
过去(Python < 3.9): 你不能写
list[str],Python 解释器会报错。为了告诉编辑器“这是一个只装字符串的列表”,必须从typing模块导入大写的List。 -
Python
from typing import List
names: List[str] = ["Alice", "Bob"] # 正确
-
现在(Python >= 3.9): Python 进行了升级,支持直接在原生类型上使用方括号。
-
Python
names: list[str] = ["Alice", "Bob"] # 现代 Python 推荐写法
它们的核心区别
为什么在 LangGraph 示例中常看到大写的 List?
你可能会问:“既然现在推荐小写的 list,为什么很多教程(包括 LangGraph 官方文档)还在用大写的 List?”
原因主要有两个:
-
向后兼容性:很多库需要支持还在运行 Python 3.8 的用户,所以坚持使用
typing.List。 -
习惯力量:很多资深开发者已经习惯了从
typing导入所有类型。
Optional
Optional 的作用可以概括为:声明这些字段的初始值可以是 None。
Optional[dict] 实际上是 Union[dict, None] 的简写。 它告诉 Python 解释器、IDE(如 VS Code)以及 LangGraph:
“这个字段要么是一个字典(
dict),要么什么都没有(None)。”
class ReflectionState(TypedDict):
user_request: str
draft: dict | None # 等同于 Optional[dict]
critique: dict | None
refined_code: dict | None
Annotated:给数据打“标签” (核心难点)
这是代码中最关键的部分。Annotated 的语法是:Annotated[类型, 附加元数据]。
-
作用:它不改变数据的类型,但为 LangGraph 提供了解释说明。
-
operator.add** (即代码中的"add")**:这是告诉 LangGraph 的 Reducer(归并器) 如何更新这个字段。
operator.add
operator.add 实际上就是 Python 里的 + 号操作。
-
对于列表 (List):
[1, 2] + [3]结果是[1, 2, 3]。 -
对于整数 (Int):
10 + 5结果是15。 -
对于字符串 (Str):
"Hello" + " World"结果是"Hello World"。
if TYPE_CHECKING:
from typing import TYPE_CHECKING, Annotated, Any, NotRequired, cast
if TYPE_CHECKING:
from deepagents.backends.protocol import BACKEND_TYPES, BackendProtocol
from langchain.chat_models import BaseChatModel
if TYPE_CHECKING: 是一个非常优雅且实用的技巧,主要用于解决循环引用(Circular Imports)和提高性能
核心作用:解决循环引用
这是最常见的使用场景。
-
冲突点:假设
Agent类需要引用Backend类做类型标注,而Backend类又需要引用Agent类。如果直接import,Python 在运行时会抛出循环引用错误。 -
解决方案:将
import语句放在if TYPE_CHECKING:块中。由于TYPE_CHECKING在运行时(Runtime)始终为False,而在类型检查工具(如 MyPy, Pyright 或 IDE)运行时为True,这样就绕开了运行时的引用死循环。
核心作用:优化启动性能
-
减少开销:像
langchain.chat_models这样的大型库,包含大量的依赖项。如果你的代码只需要用它来做类型声明(比如:model: BaseChatModel),而不需要在当前文件实例化它。 -
效果:放在这个块里后,Python 解释器在执行时完全不会加载这些模块,从而加快了脚本的启动速度并节省了内存。
环境变量env
基础用法:读取与设置
首先需要导入内置的 os 模块。
读取环境变量
读取变量有两种主要方式,它们的行为在变量不存在时会有所不同:
-
直接访问:
os.environ["KEY"]- 如果键不存在,会抛出
KeyError。适用于程序运行必不可少的变量。
- 如果键不存在,会抛出
-
安全访问:
os.environ.get("KEY", "default_value")- 如果键不存在,返回
None或你设定的默认值。这是最推荐的做法,可以增加程序的健壮性。
- 如果键不存在,返回
设置环境变量
你可以像操作字典一样设置变量:
import os
# 设置 DeepSeek API Key
os.environ["DEEPSEEK_API_KEY"] = "sk-1234567890"# 读取确认
print(os.environ.get("DEEPSEEK_API_KEY"))
大模型调用时是怎么识别环境变量中的apikey的
import os
from dotenv import load_dotenv
from openai import OpenAI # 假设使用兼容 OpenAI 格式的 SDK
# 1. 加载 .env 文件中的变量到系统环境变量中
load_dotenv()
# 2. 从环境变量中提取 Key
# 使用 os.getenv 的好处是:如果变量不存在,它会返回 None 而不是报错
api_key = os.getenv("DEEPSEEK_API_KEY")
if not api_key:
raise ValueError("未找到 API Key,请检查环境变量或 .env 文件!")
# 3. 初始化客户端并将 Key 注入
client = OpenAI(
api_key=api_key,
base_url="https://api.deepseek.com" # 以 DeepSeek 为例
)
# 4. 调用模型
response = client.chat.completions.create(
model="deepseek-chat",
messages=[{"role": "user", "content": "你好"}]
)
print(response.choices[0].message.content)
文件路径
SUBAGENTS_CONFIG = Path(file).parent / "subagent.yaml"
-
Path(file): 获取当前正在运行的这个 Python 文件的绝对路径。 -
.parent: 获取该文件所在的父目录(即当前文件夹)。 -
/ "subagent.yaml":** 使用 pathlib 库的路径拼接功能**,指向该文件夹下的subagent.yaml文件。 -
作用: 定义子智能体(Sub-agents)的配置文件路径。这个 YAML 文件通常包含子智能体的名称、角色描述、权限等核心设置。
SKILLS_DIR = str(Path(file).parent / "skills")
-
"skills": 指向当前文件夹下的一个名为skills的子目录。 -
str(...): 将路径对象转换成普通的字符串格式。 -
作用: 定义技能目录的路径。在 Agent 架构中,
skills文件夹通常存放 Python 脚本,每个脚本代表一个工具(Tool)或动作(Action),比如“搜索网页”、“读写数据库”等。
Socket
https://www.runoob.com/python/python-socket.html
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 文件名:client.py
import socket # 导入 socket 模块
s = socket.socket() # 创建 socket 对象
host = socket.gethostname() # 获取本地主机名
port = 12345 # 设置端口号
s.connect((host, port))
print s.recv(1024)
s.close()
后端项目创建虚拟环境(windows)
- 打开命令提示符或 PowerShell:
按下 Win + R,输入 cmd 或 powershell 并按回车。
-
导航到你的项目目录:
-
cd 路径\到\你的\项目
-
创建虚拟环境:
-
python -m venv video_env
-
激活虚拟环境:
-
video_env\Scripts\activate
-
激活成功后,命令行前面会出现 (video_env) 前缀。
-
安装依赖包:
-
pip install -r requirements.txt
-
查看已安装的包:
-
pip list
-
退出虚拟环境:
-
deactivate
-
每次使用项目时重新激活:
-
video_env\Scripts\activate
-
如果在cursor中激活虚拟环境失败:
PS G:\cursor练习\video_doc_v2> video_env\Scripts\activate
video_env\Scripts\activate : 无法加载文件 G:\cursor练习\video_doc_v2\video_env\Scripts\A
ctivate.ps1,因为在此系统上禁止运行脚本。有关详细信息,请参阅 https:/ go.microsoft.com/fw
link/?LinkID=135170 中的 about_Execution_Policies。
在 Windows 上,当你尝试激活 Python 虚拟环境时,遇到了一个关于 PowerShell 执行策略的错误。这是因为 Windows 默认的 PowerShell 执行策略不允许运行脚本。你可以通过以下步骤来解决这个问题:
解决方案:修改 PowerShell 执行策略
- 打开 PowerShell 以管理员身份运行:
- 在开始菜单中搜索 "PowerShell",右键点击 "Windows PowerShell",选择 "以管理员身份运行"。
- 查看当前执行策略:
- 输入以下命令查看当前的执行策略:
-
Get-ExecutionPolicy
- 修改执行策略:
- 将执行策略设置为 RemoteSigned,这允许运行本地脚本:
-
Set-ExecutionPolicy RemoteSigned - 如果系统提示确认更改,输入 Y 并按回车。
- 关闭 PowerShell 并重新打开:
- 关闭管理员权限的 PowerShell 窗口,然后在你的项目目录中重新打开 PowerShell。
- 激活虚拟环境:
- 现在你可以尝试再次激活虚拟环境
pytest使用
https://download.csdn.net/blog/column/12476479/135565920
pytest的组成部分
pytest由两部分组成: ❶ 用例主体部分(通常单独放在一个py文件):主体部分写测试用例 ❷ 用例运行语句(通常放在一个main文件):执行测试用例 一个简单的示例如下:
- 用例主体文件:test_lesson1.py
"""
用例主体部分:
定义1个用例的函数,需要带上test关键字
与之前的函数不同的是:在pytest框架下,可以不写调用语句,也可以执行函数的内容
"""
#主体例子1:
def test_case():
print("用例被运行")
#主体例子2:烤鸭1.0
def test_duck():
print("-----烤鸭店利润计算器开始⼯作------")
price1 = int(input("请输⼊烤鸭的进货价:")) # input传递来的值,都是str
price2 = int(input("请输⼊烤鸭的售卖价:"))
num = int(input("请输⼊今天卖出的烤鸭数量:"))
result = (price2 - price1) * num
print("今天的烤鸭利润是{}元".format(result))
- 用例执行文件:main.py pytest 通过一个list接受参数,所以调用main函数时()里加上[]
#用例执行语句:
import pytest
pytest.main(["-s"])
- 完整代码如下:
*import* os
*import* pytest
*import* tempfile
*import* shutil
*from* app *import* download_video
class TestVideoDownloader:
*# 设置测试环境*
@pytest.fixture(*scope*="function")
def **temp_dir**(*self*):
*# 创建临时目录*
temp_dir = tempfile.mkdtemp()
*yield* temp_dir
*# 测试后清理*
shutil.rmtree(temp_dir)
def **test_download_valid_video**(*self*, *temp_dir*):
"""测试下载有效的视频链接"""
*# 使用一个稳定的短视频作为测试源*
video_url = "https://www.youtube.com/watch?v=jNQXAC9IVRw" *# YouTube第一个视频*
output_path = os.path.join(*temp_dir*, "test_video")
success, result = download_video(video_url, output_path)
*# 验证下载是否成功*
*assert* success, f"下载失败,错误: {result}"
*assert* os.path.exists(result), "下载的视频文件不存在"
*assert* os.path.getsize(result) > 0, "下载的视频文件大小为0"
def **test_download_invalid_video**(*self*, *temp_dir*):
"""测试下载无效的视频链接"""
*# 使用一个无效的视频链接*
video_url = "https://www.youtube.com/watch?v=invalid_video_id"
output_path = os.path.join(*temp_dir*, "test_invalid_video")
success, result = download_video(video_url, output_path)
*# 验证下载应该失败*
*assert* not success, "无效链接应该下载失败,但却成功了"
*assert* isinstance(result, str), "错误信息应该是字符串"
def **test_download_video_with_special_characters**(*self*, *temp_dir*):
"""测试下载包含特殊字符的视频标题"""
*# 这个视频标题通常包含特殊字符*
video_url = "https://www.youtube.com/watch?v=dQw4w9WgXcQ" *# Rick Astley - Never Gonna Give You Up*
output_path = os.path.join(*temp_dir*, "test_special_chars")
success, result = download_video(video_url, output_path)
*# 验证下载是否成功*
*assert* success, f"下载失败,错误: {result}"
*assert* os.path.exists(result), "下载的视频文件不存在"
def **test_download_short_video**(*self*, *temp_dir*):
"""测试下载简短视频"""
*# 使用一个较短的视频*
video_url = "https://www.youtube.com/watch?v=jNQXAC9IVRw" *# 只有18秒*
output_path = os.path.join(*temp_dir*, "test_short_video")
success, result = download_video(video_url, output_path)
*# 验证下载是否成功*
*assert* success, f"下载失败,错误: {result}"
*assert* os.path.exists(result), "下载的视频文件不存在"
*# 用于手动运行测试*
*if* __name__ == "__main__":
pytest.main(["-xvs", "test_video_downloader.py"])
如何运行pytest文件
-
手动执行py文件,直接编辑器上点击运行
-
命令行输入
-
pytest -xvs test_video_downloader.py
pytest运⾏时携带的参数
- -s
- 表示开启终端交互,其作⽤是可以让打印的内容输出显示在终端中,或者可以在终端中与⽤例中的输⼊操作进⾏交互
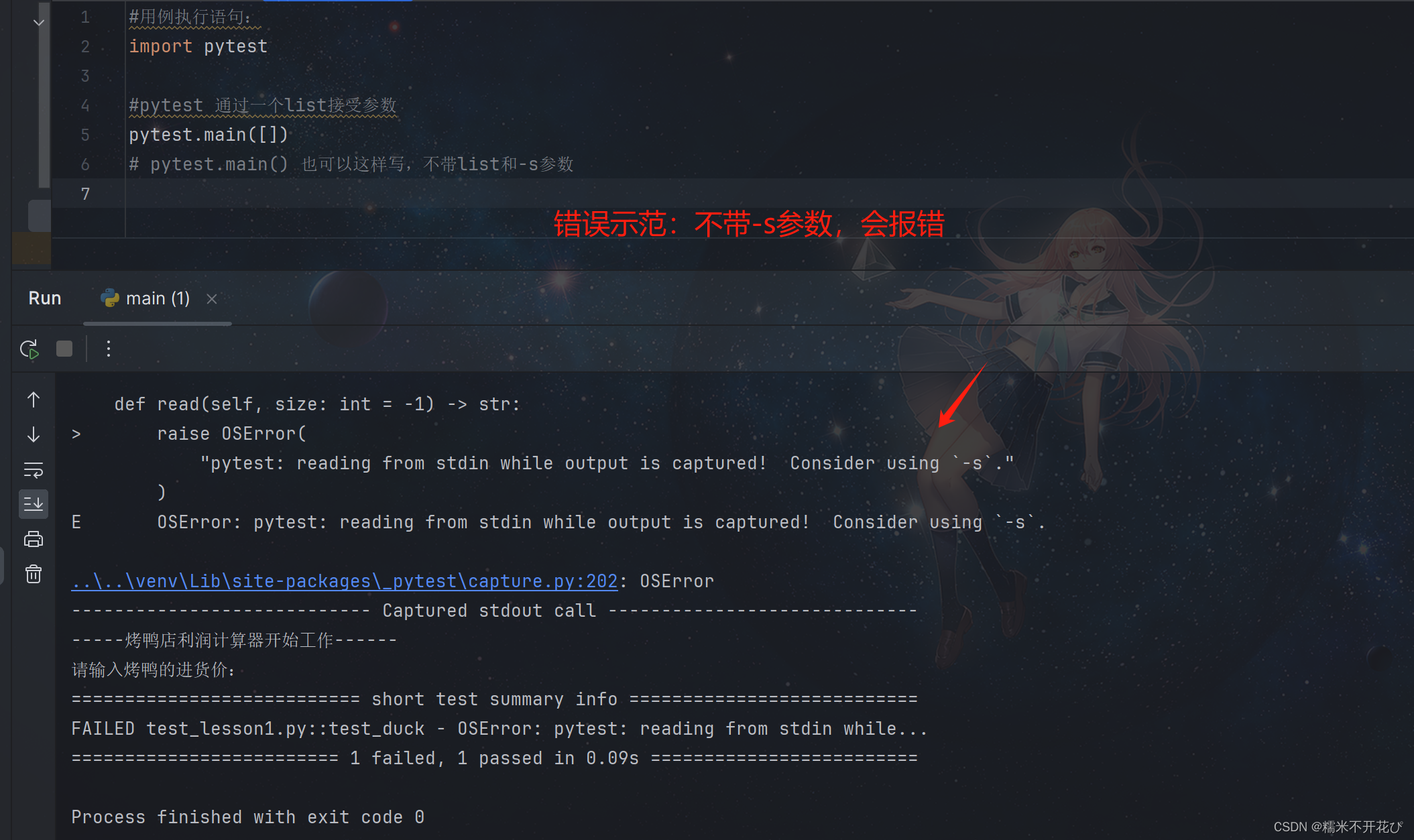
- -v
-v: 表示详细输出更详细的输出,包括每个测试⽤例的详细结果和其他相关信息,例如测试⽤例所在的模块、⽂件路径等。 还是上面的代码,加上-v后的终端显示效果:
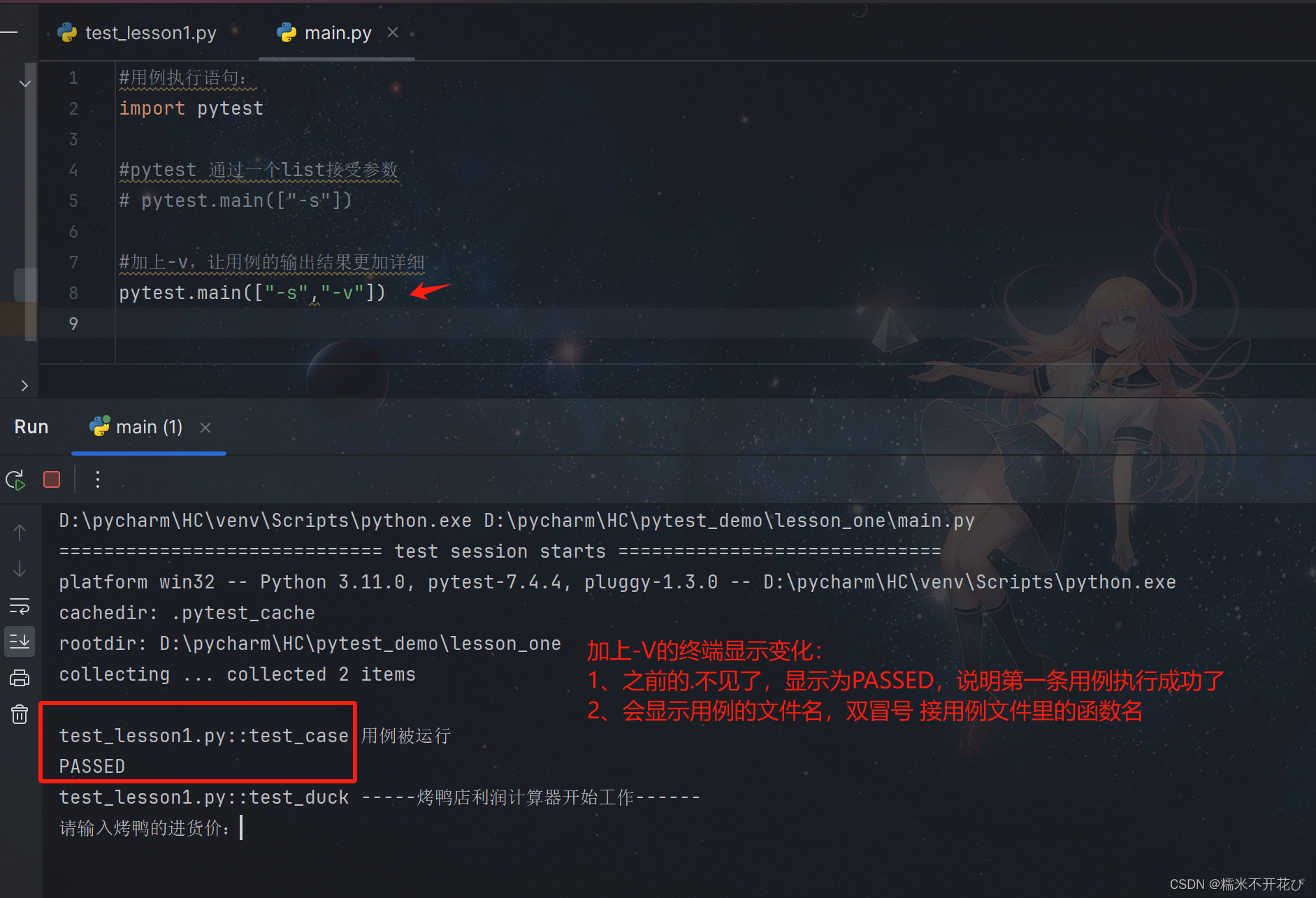
pytest指定运行用例
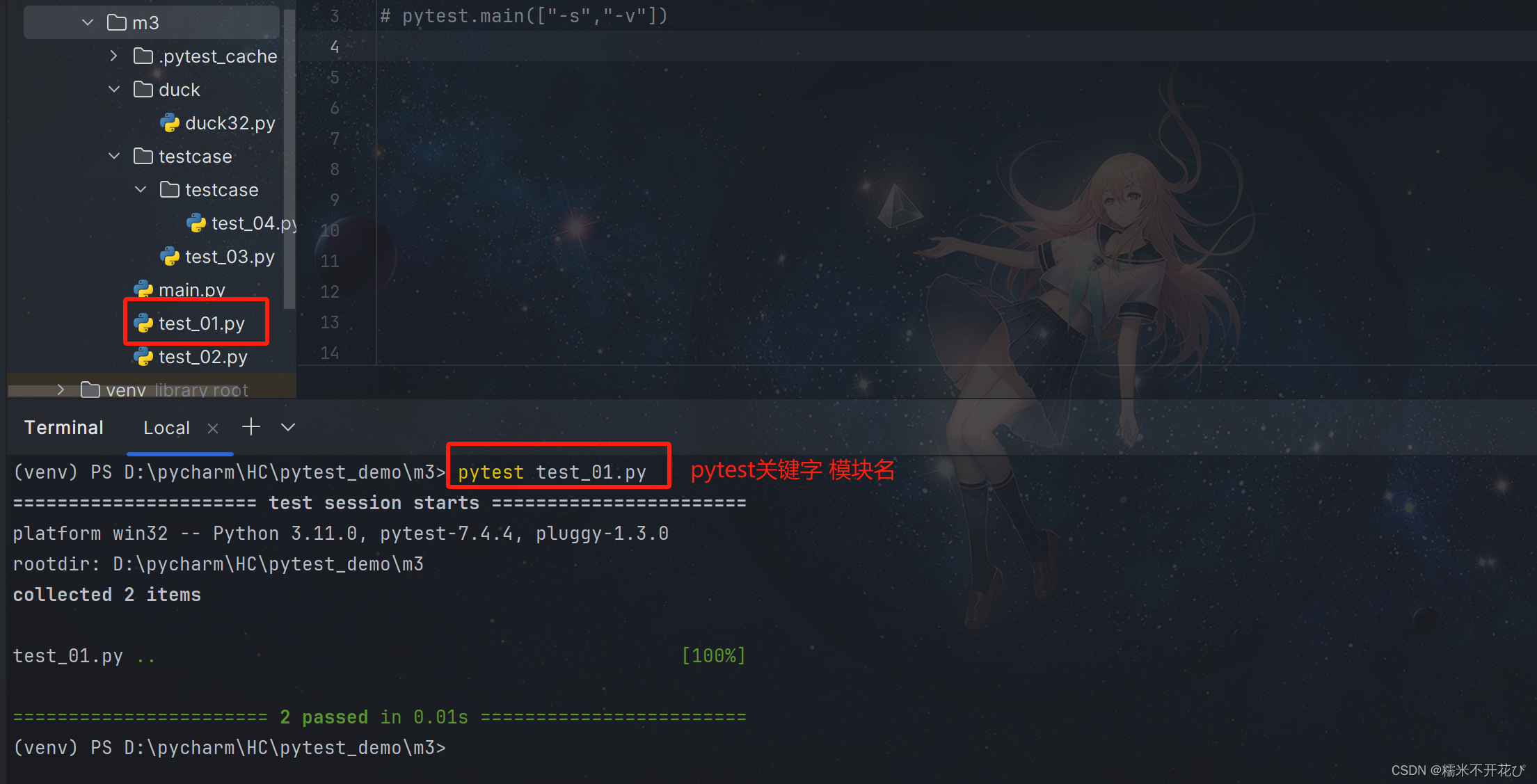
像上面的m3用例目录下,有很多不同的模块,当我们只需要执行某一模块的用例、或者某一个模块的某个类、或者某个类下面的某个用例,就可以进行指定:
① 指定运行其中一个模块的用例:
pytest 模块名
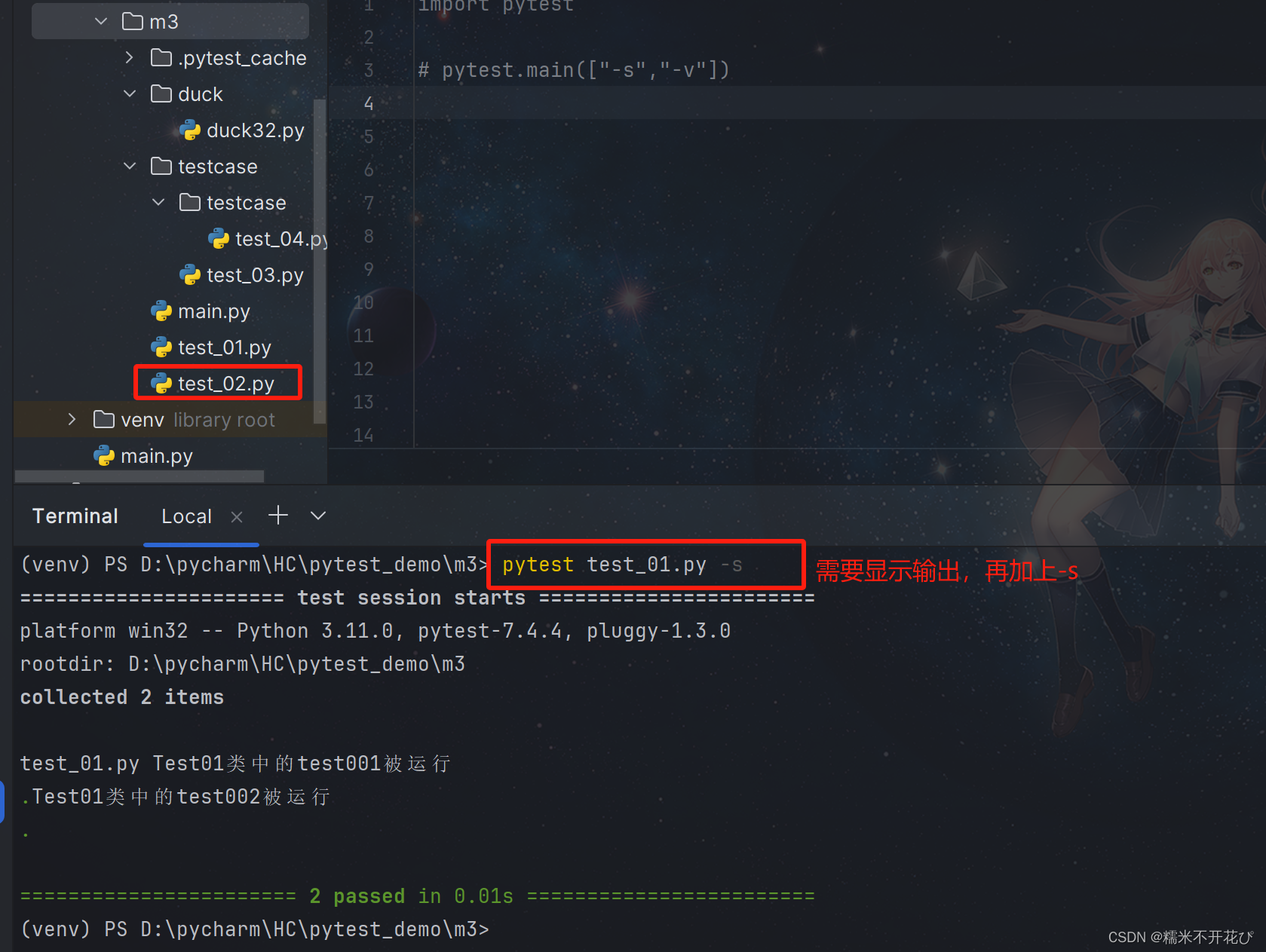
如果需要显示输入内容,再加上-s即可:
pytest 模块名 -s
② 指定运行某个模块中的某个类:
pytest 模块名::函数名/类名 #(双冒号表示模块中的下一层)
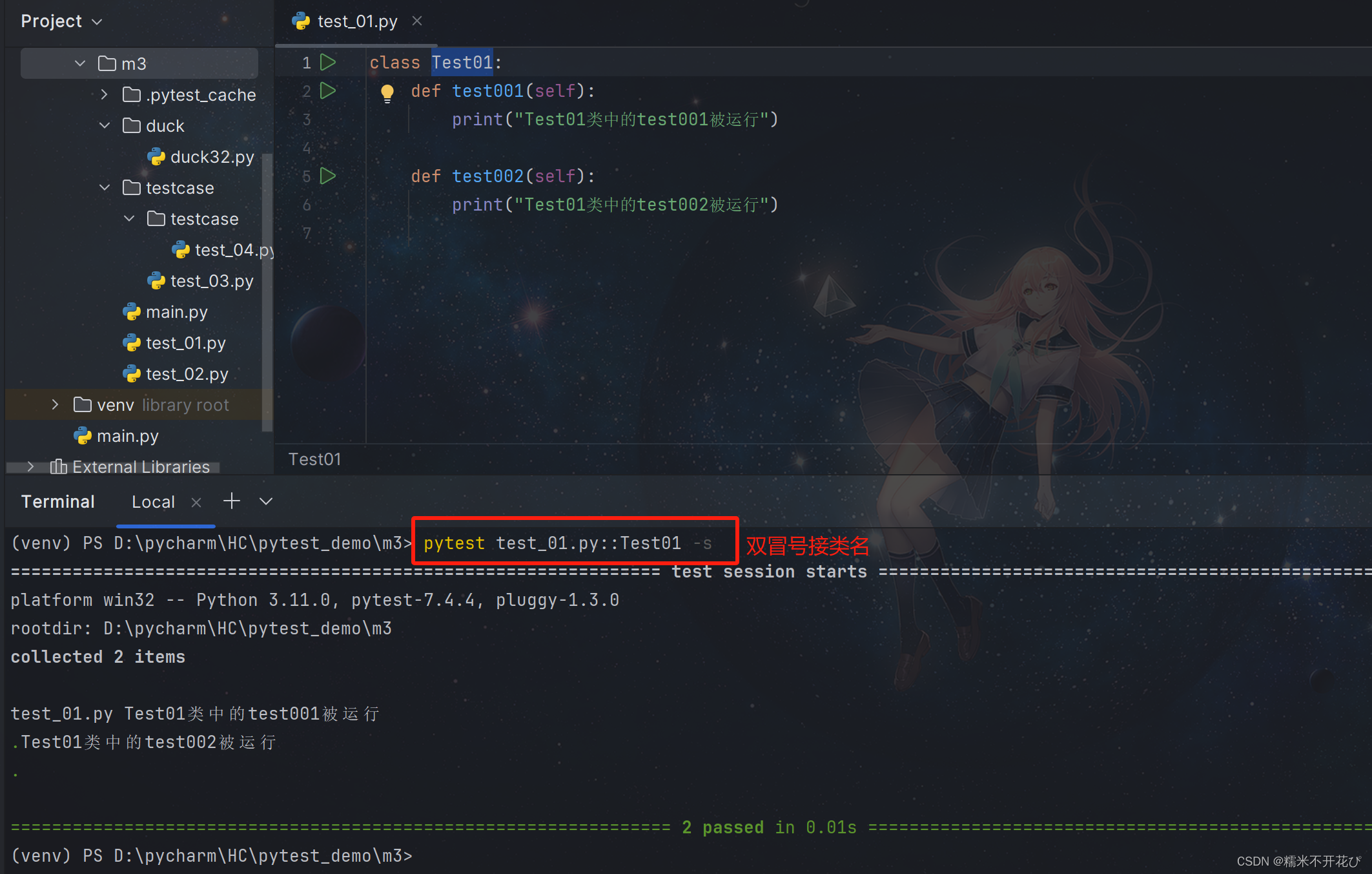
③ 指定运行某个模块中的某个类下面的某个用例:
pytest 模块名::函数名::类名
指定m3文件夹下 -> test_01这个模块 -> Test01这个类 -> 下面的test002这个用例
在main文件中指定模块下类下面的某个用例:
写法和终端差不多,只是多了标识符、双引号、逗号
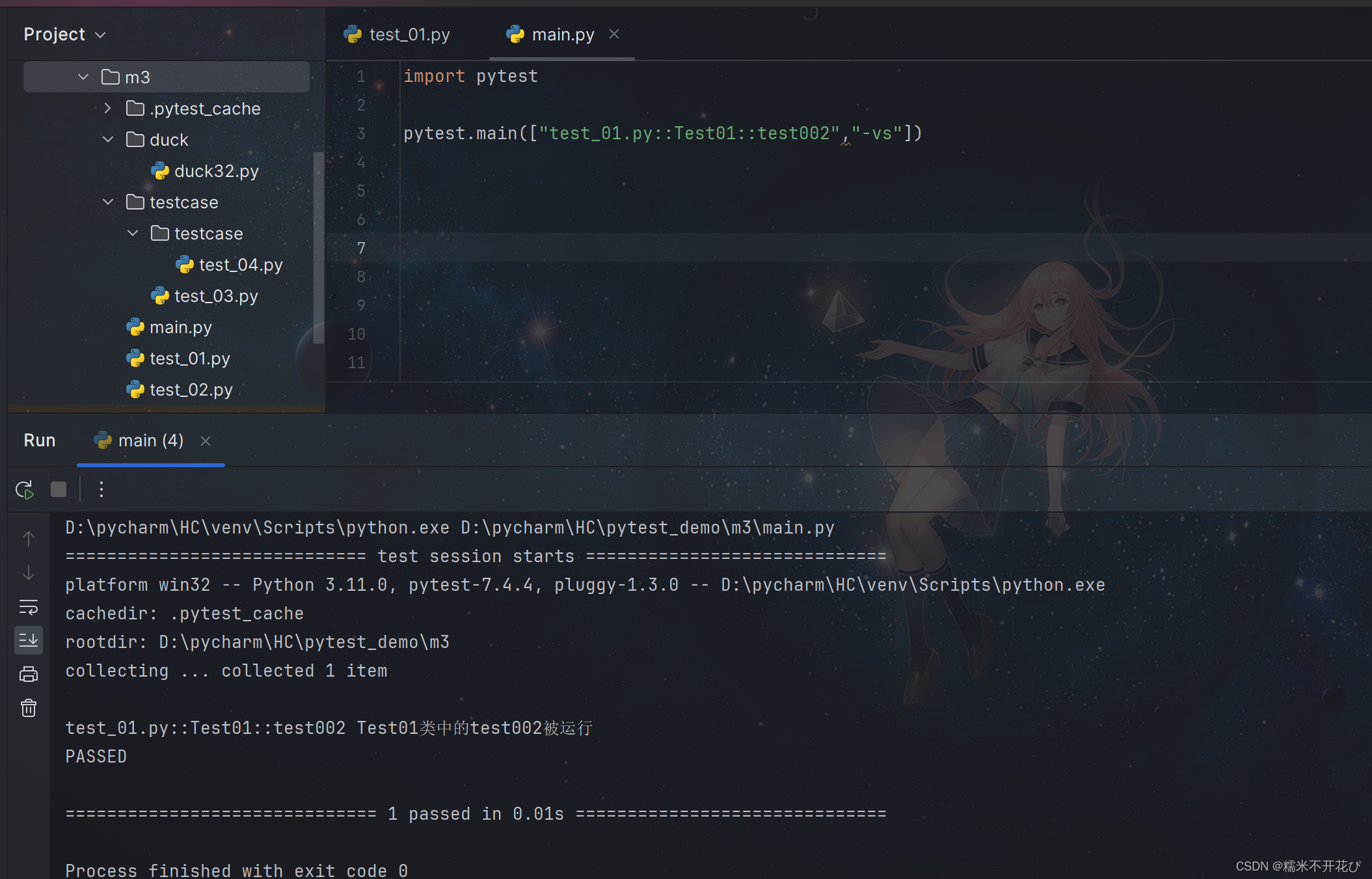
④ 指定文件夹运行用例:
pytest.main(["文件名","-sv"])
指定m3文件夹下 -> testcase这个文件夹下的所有用例
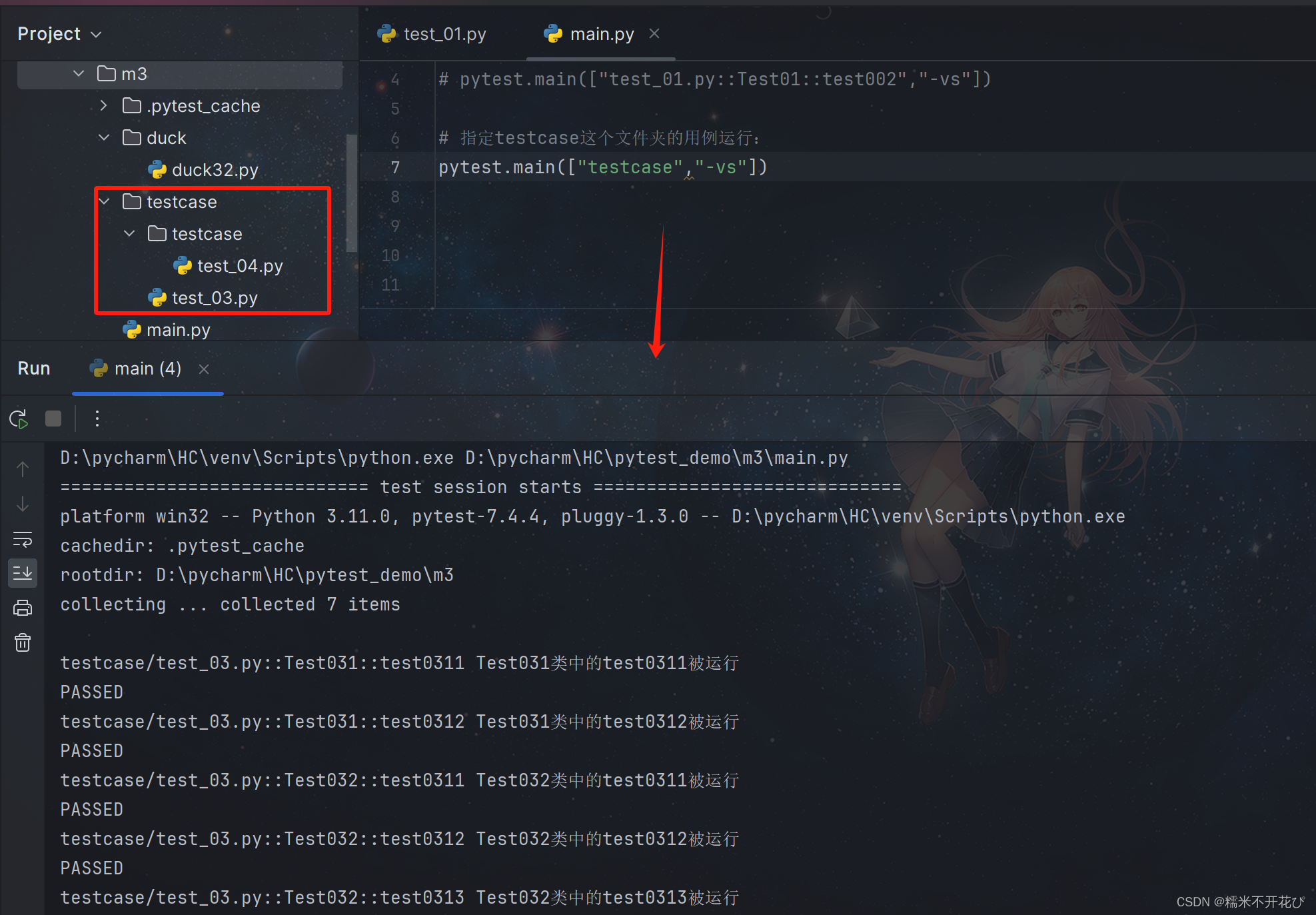
指定文件夹下的子级文件的用例运行:
pytest.main(["文件名/子文件夹名","-sv"])
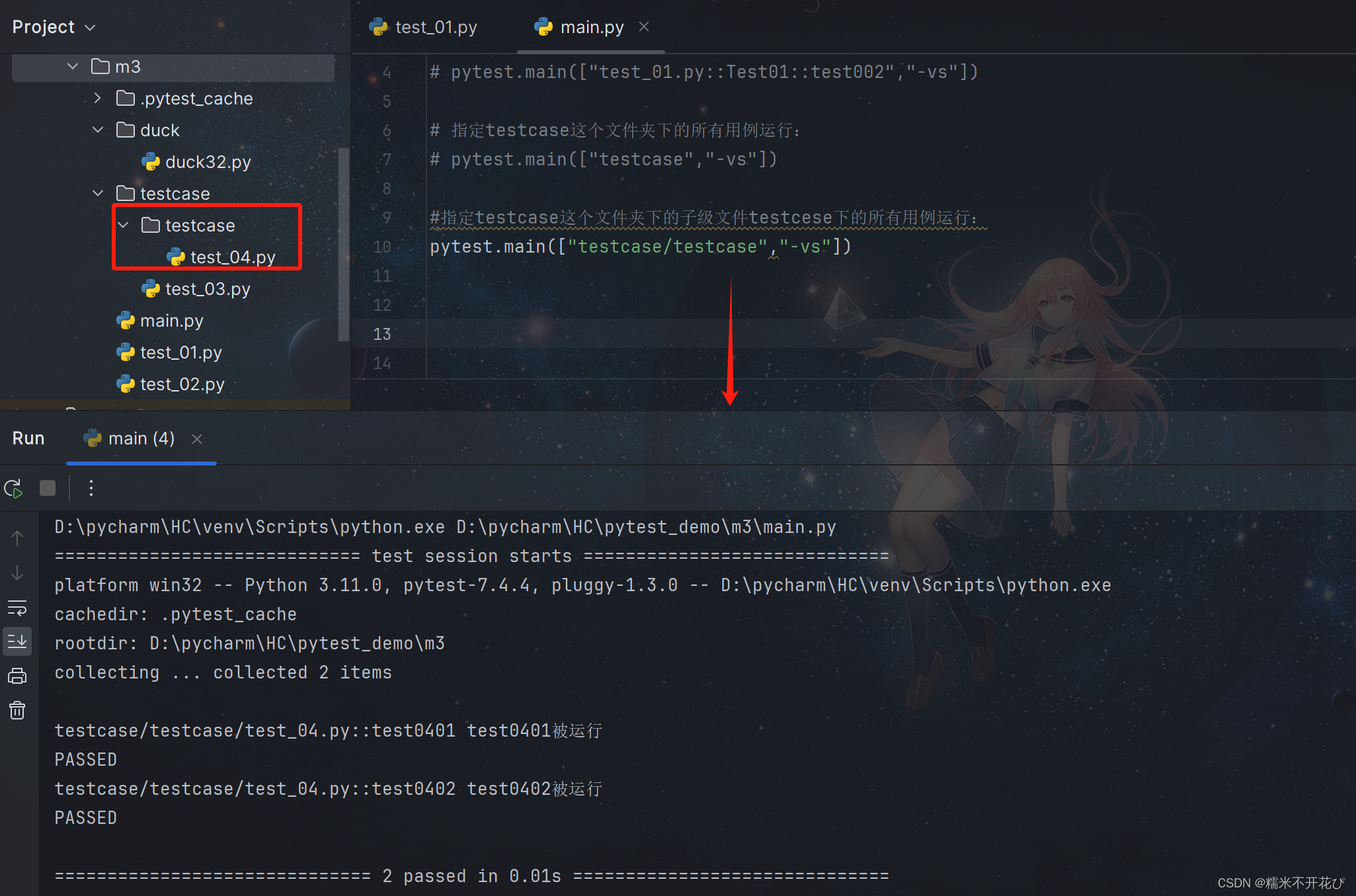
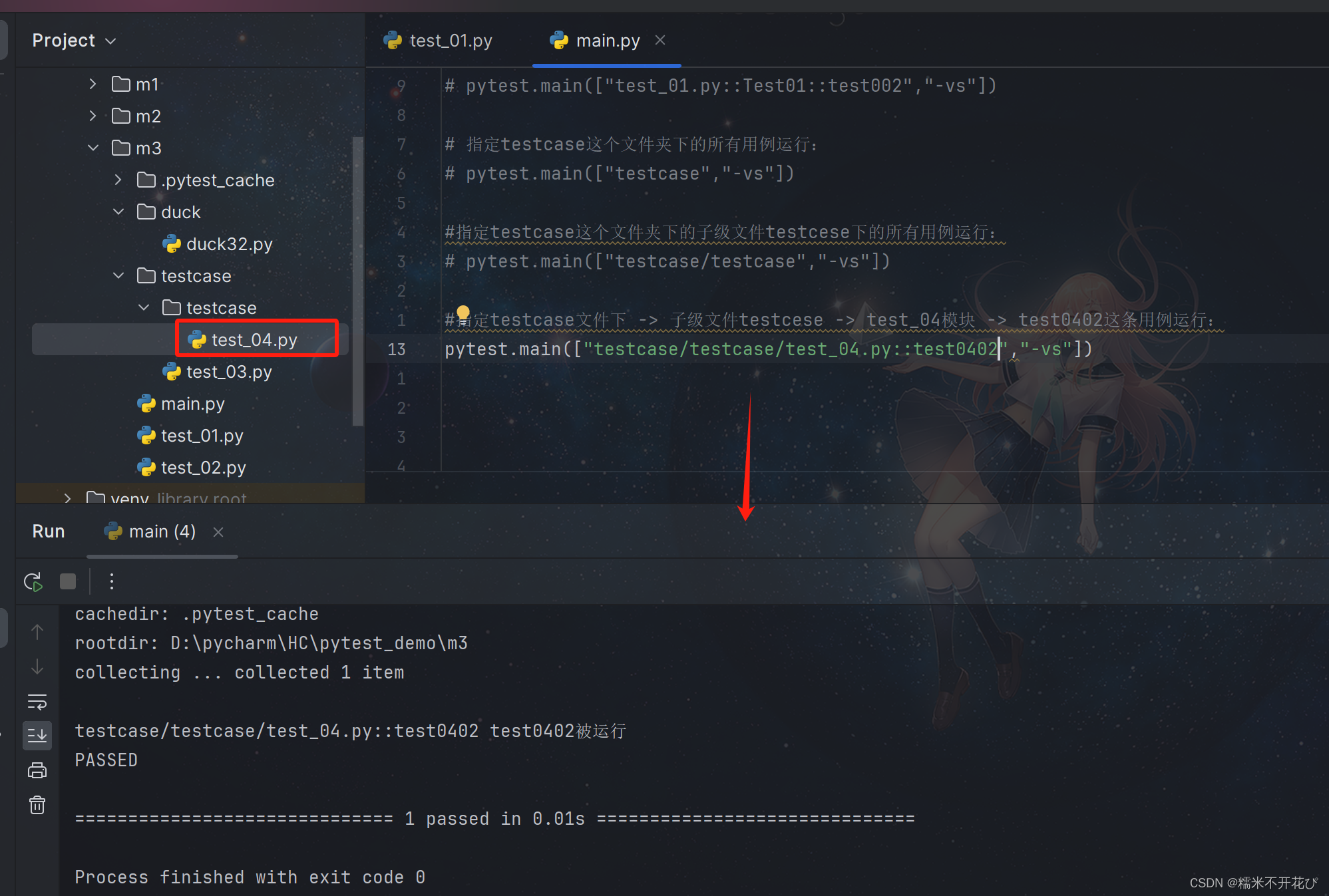
指定文件夹下 -> 子级文件 - > 模块中的某个用例运行:
pytest.main(["文件名/子文件夹名/模块名::用例名","-sv"])
rich库
rich 的强大之处在于它将终端从“纯文本工具”变成了“可视化面板”。以下通过几个核心场景,展示 rich 的常用组件及代码实现。
基础布局与面板 (Panel & Columns)
Panel 可以给文字加上边框和标题,而 Columns 则可以将内容并排显示。
from rich import printfrom rich.panel import Panel
from rich.columns import Columns
# 创建几个带边框的面板
panels = [Panel(f"项目 {i}", expand=False, border_style="cyan") for i in range(3)]
print(Columns(panels))
交互式数据表 (Table)
这是最常用的组件之一,支持自动列宽、标题高亮和边框样式。
Python
from rich.table import Table
from rich.console import Console
console = Console()
table = Table(title="LLM 模型对比", show_header=True, header_style="bold magenta")
table.add_column("模型名称", style="dim", width=12)
table.add_column("参数量", justify="right")
table.add_column("开源状态", justify="center")
table.add_row("Llama-3", "70B", "[green]Yes[/green]")
table.add_row("GPT-4", "Unknown", "[red]No[/red]")
table.add_row("DeepSeek", "67B", "[green]Yes[/green]")
console.print(table)
实时状态与进度 (Status & Progress)
在处理长时间运行的任务(如模型推理或文件下载)时,这些组件能显著提升用户体验。
加载状态 (Spinner)
Python
import time
from rich.console import Console
console = Console()
with console.status("[bold green]正在加载模型文件...", spinner="dots"):
# 模拟耗时操作
time.sleep(3)
console.log("模型加载完成!")
多任务进度条 (Progress)
Python
from rich.progress import Progress
import time
with Progress() as progress:
task1 = progress.add_task("[red]下载数据集...", total=100)
task2 = progress.add_task("[green]模型转换...", total=100)
while not progress.finished:
progress.update(task1, advance=0.5)
progress.update(task2, advance=0.3)
time.sleep(0.02)
增强调试 (Traceback & Inspect)
rich 可以接管 Python 的默认报错信息,让排查错误变得赏心悦目。
Python
from rich.traceback import install
from rich import inspect
# 安装异常处理器,之后的报错都会以富文本形式展示
install(show_locals=True)
# 使用 inspect 查看任何 Python 对象的“底细”
my_list = [1, 2, 3]
inspect(my_list, methods=True)
# 故意制造一个错误来测试 Traceback# 1 / 0
渲染 Markdown 与 语法高亮 (Markdown & Syntax)
你可以直接在终端阅读文档或高亮代码片段。
Python
from rich.markdown import Markdown
from rich.syntax import Syntax
from rich.console import Console
console = Console()
# 渲染 Markdown
md_text = "# 这是标题\n- 列表项 1\n- **加粗文本**"
console.print(Markdown(md_text))
# 渲染高亮代码
code = """
def hello_world():
print("Hello, Rich!")
"""
syntax = Syntax(code, "python", theme="monokai", line_numbers=True)
console.print(syntax)
prompt_toolkit 包
专门用于构建交互式的命令行界面(CLI)。
核心功能亮点
它不仅是获取用户输入,而是把整个终端变成了一个“微型编辑器”。
-
语法高亮(Syntax Highlighting):可以在用户输入时实时改变文字颜色(利用
Pygments)。 -
自动补全(Auto-completion):支持弹出式菜单,可以根据上下文提示命令、文件名或 AI 指令。
-
多行编辑(Multi-line Editing):支持像编辑器一样上下移动光标、换行,而不是单行输入。
-
输入提示(Auto-suggestion):类似鱼壳(Fish shell),会根据历史记录灰度显示建议,按右箭头即可填充。
-
搜索历史(History Search):支持类似
Ctrl+R的增量搜索。 -
鼠标支持:你甚至可以用鼠标点击终端里的选项或移动光标。
工作原理:Buffer 机制
prompt_toolkit 的核心是一个 Buffer(缓冲区)。 用户输入的每一个字都存在 Buffer 里。Completer、Lexer(高亮器)和 Validator(验证器)都会实时监控这个 Buffer。
当用户按下键盘时:
-
事件循环(Event Loop) 捕获按键。
-
KeyBindings 检查这是否是一个特殊指令(如回车提交)。
-
Completer 扫描当前 Buffer 的内容并
yield出补全建议。 -
Renderer 重新绘制屏幕,显示最新的文字、颜色和弹出菜单。
用法
contextlib
@asynccontextmanager
它的作用是让你能够用“函数+ yield”的简洁方式,编写一个支持 async with 语法的上下文管理器。
核心场景:资源的安全管理
在异步程序中,我们经常需要处理数据库连接、网络请求或文件 IO。这些资源必须遵循“打开 -> 使用 -> 必须关闭”的流程。
如果没有上下文管理器,你可能需要写很多 try...finally 来确保即使程序出错,资源也能被释放:
# 繁琐的写法
db = await connect()
try:
await do_something(db)
finally:
await db.close()
使用 @asynccontextmanager 后,可以简化为:
async with get_db() as db:
await do_something(db)
# 退出缩进时,db.close() 会自动被执行
标准写法示例
通过装饰器,你可以把一个异步生成器变成一个上下文管理器:
from contextlib import asynccontextmanager
@asynccontextmanagerasync
def get_checkpointer():# --- 【__aenter__ 部分】 ---# 这里的代码在进入 async with 时执行
print("正在连接数据库...")
db = await open_sqlite_connection()
try:
yield db # yield 出的对象就是 'as' 后面的变量finally:
# --- 【__aexit__ 部分】 ---# 无论 with 块内是否报错,这里的代码都会执行
print("正在关闭数据库...")
await db.close()
执行流程解析
当你执行 async with get_checkpointer() as checkpointer: 时,程序经历了以下步骤:
-
启动:执行函数直到遇到
yield。 -
挂起:将
yield后的对象返回给调用者(即as后面的变量),函数在这里“暂停”。 -
业务执行:执行
async with缩进块内部的所有代码(比如你的_async_main_loop)。 -
恢复与清理:一旦
async with块执行完毕或抛出异常,程序会跳回yield之后的位置,执行finally块里的清理代码。
ContextVars
from contextvars import ContextVar
# ContextVar(上下文变量),它是 Python contextvars 模块提供的一种机制,
# 专门用于在异步编程(asyncio)或多线程环境中安全地存储和传递“全局”数据。
_CURRENT_MEMORY: ContextVar[str] = ContextVar("evo_memory_current", default="")
语法层面的类型:ContextVar
从 Python 对象的角度来看,_CURRENT_MEMORY 的类型是 contextvars.ContextVar。
-
它不是一个简单的字符串,而是一个容器(或者说是一个上下文句柄)。
-
如果你直接打印
type(_CURRENT_MEMORY),你会得到<class 'contextvars.ContextVar'>。 -
操作方式:你不能直接像字符串那样对它进行加减,必须通过
.get()获取值,通过.set(value)存入值。
存储内容的类型:str(字符串)
在定义时的泛型标注 ContextVar[str] 表明,这个容器规定只能存放字符串类型的数据。
-
在这个中间件里,它存放的是
MEMORY.md文件的文本内容。 -
默认值
default=""也是一个空字符串。
为什么python项目无法极致高并发
. 全局解释器锁(GIL)
Python 的 CPython 解释器使用 GIL,使得同一进程内同一时刻只能有一个线程执行 Python 字节码。这意味着:
-
多线程对 CPU 密集型任务无效:多个线程无法同时利用多核 CPU 并行计算。
-
I/O 密集型任务仍可获益:线程在等待 I/O 时会释放 GIL,因此线程在 I/O 场景下仍可并发,但线程切换和锁竞争会带来额外开销。
与之对比,Go 的 goroutine、Java 的线程(基于操作系统线程)都可以真正并行执行计算任务,充分发挥多核优势。
线程模型与内存开销
Python 的线程是操作系统级别的线程,每个线程占用较多内存(约 8MB 栈空间),且创建和销毁成本较高。因此,在需要大量并发连接(例如 10k+ 连接)的场景下,使用线程模型会消耗大量内存并导致频繁的上下文切换。
虽然可以使用 asyncio 在单线程内实现高并发(见下文),但这也意味着无法利用多核 CPU。
异步编程的局限
Python 3.4+ 引入 asyncio,通过事件循环在单线程内管理大量 I/O 等待任务,实现高并发。这种模型非常高效,适合网络爬虫、Web 服务器等 I/O 密集型应用。但仍有局限:
-
单线程计算瓶颈:如果某个协程执行 CPU 密集计算(没有
await),会阻塞整个事件循环,影响所有其他协程。 -
生态兼容性:许多 Python 库是同步阻塞的,若在
async代码中调用这些库,会阻塞事件循环。需要专门的异步库(如aiohttp、asyncpg)才能发挥优势。 -
调度开销:事件循环本身的调度虽轻量,但无法利用多核,仍需通过多进程或混合模型扩展。
进程模型与通信成本
为利用多核 CPU,Python 通常采用多进程(multiprocessing)将任务分散到多个进程。但多进程:
-
内存开销大(每个进程有独立内存空间)。
-
进程间通信(IPC)复杂且速度较慢(如
Queue、Pipe、共享内存)。 -
启动和销毁进程成本远高于线程或协程。
语言动态性与性能开销
Python 是动态类型语言,对象模型、属性访问、方法调用等均有额外开销。在高并发场景下,即使是简单的请求处理,也可能因解释器开销而影响吞吐量。相比之下,编译型语言(如 Go、Java、C#)或 JIT 优化的语言(如 Node.js 的 V8)在相同硬件上能处理更多请求。
实际工程中的表现
尽管有上述限制,Python 在 I/O 密集型高并发场景下仍有不俗表现,例如:
-
Web 框架:使用
asyncio+FastAPI或Sanic,单进程可轻松处理数千并发连接。 -
数据库驱动:
asyncpg连接池 +asyncio可以实现极高的数据库查询并发。 -
反向代理:像
Uvicorn这样的 ASGI 服务器,通过多进程 + 每个进程内事件循环,能利用多核并处理大量连接。
但若要追求极致高并发(例如超过数万并发连接且包含复杂计算),通常需要:
-
将计算密集型任务剥离到其他语言编写的微服务。
-
使用
asyncio+multiprocessing混合模型。 -
部署多个 Python 进程,并通过 Nginx 等负载均衡分发请求。
资料
https://guangzhengli.com/blog/zh/indie-hacker-tech-stack-2024/